目录
安装及配置
准备工作:
- 安装 JDK
- 下载 ZooKeeper 安装包
接下来创建 ZooKeeper 3.7.0 伪集群:
- 解压:
xxxxxxxxxxtar zxvf apache-zookeeper-3.7.0-bin.tar.gz- 复制 ZooKeeper 目录:
xxxxxxxxxxfor i in `seq 1 4`; do cp -r apache-zookeeper-3.7.0-bin apache-zookeeper-3.7.0-bin-$i ; done- 创建 zoo.cfg:
xxxxxxxxxxfor i in `seq 1 4`; do cp apache-zookeeper-3.7.0-bin-$i/conf/zoo_sample.cfg apache-zookeeper-3.7.0-bin-$i/conf/zoo.cfg ; done常用配置:
- tickTime:ZooKeeper 中的时间单元。ZooKeeper 中的所有时间都以该时间单元为基础,进行整数倍配置。例如 Session 的最小超时时间是 2 * tickTime
- initLimit:Follower 启动时,会从 Leader 同步状态,同步完成后,才会被 Leader 加到 Follower 列表。Leader 允许 Follower 在 initLimit 时间内完成该工作。通常情况下,不用在意该参数的设置。如果集群的数据量很大,Follower 在启动时,从 Leader 上同步数据的时间也会相应变长,在这种情况下,有必要适当调大该参数
- syncLimit:在运行过程中,Leader 负责与集群中的所有节点进行通信,例如通过心跳检测机制,来检测节点的存活状态。如果 Leader 发出的心跳包在 syncLimit 时间之后,还没有从 Follower 收到响应,那么就认为该 Follower 已不在线。注意:不要把该参数设置得过大,否则可能掩盖一些问题
- dataDir:存储快照文件的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数 dataLogDir, 事务日志的写性能直接影响 ZooKeeper 的性能
- dataLogDir:事务日志输出目录。尽量给事务日志配置单独的磁盘或是挂载点,这将极大地提升 ZooKeeper 的性能
- clientPort:客户端连接 ZooKeeper Server 的端口,即对外服务端口,一般设置为 2181
- server.x=[hostname]:nnnnn[:nnnnn]:其中 x 是数字,与 myid 文件中的 id 一致。右边可以配置两个端口,第一个端口用于 Follower 和 Leader 之间的数据同步和其它通信,第二个端口用于 Leader 选举过程中的投票通信
为所有节点创建数据目录、事务日志目录、myid 文件(每个节点的 myid 都不一样)
xxxxxxxxxxfor i in `seq 1 4` ; do mkdir zkdata-$i; mkdir zkdatalog-$i; echo $i >zkdata-$i/myid; done- 修改 zoo.cfg 配置:
xxxxxxxxxxfor i in `seq 1 4`; do sed -i "s/^clientPort=[0-9]\{1,\}/clientPort=218$i/g" apache-zookeeper-3.7.0-bin-$i/conf/zoo.cfg && sed -i "s/^dataDir=.*/dataDir=zkdata-$i\//g" apache-zookeeper-3.7.0-bin-$i/conf/zoo.cfg && echo "dataLogDir=zkdatalog-$i/" >>apache-zookeeper-3.7.0-bin-$i/conf/zoo.cfg && for i_ in `seq 1 4`; do echo "server.$i_=0.0.0.0:188$i_:288$i_" >>apache-zookeeper-3.7.0-bin-$i/conf/zoo.cfg ; done ; done- 将第 4 个节点设置为 Observer:
xxxxxxxxxxfor i in `seq 1 4`; do sed -i "s/^server.4=\(.*\):\([0-9]\{1,\}\):\([0-9]\{1,\}\)$/server.4=\1:\2:\3:observer/g" apache-zookeeper-3.7.0-bin-$i/conf/zoo.cfg ; done- 启动所有节点:
xxxxxxxxxxfor i in `seq 1 4`; do apache-zookeeper-3.7.0-bin-$i/bin/zkServer.sh start ; done- 查看所有节点的状态:
xxxxxxxxxxfor i in `seq 1 4`; do apache-zookeeper-3.7.0-bin-$i/bin/zkServer.sh status ; donePaxos 简介
ZooKeeper 在恢复模式下,选举 Leader 使用的是 Paxos 算法。Paxos 是一种分布式一致性算法,其解决的问题是:分布式系统如何就一个值达成一致。在 Paxos 中,多个节点之间就同一个值达成一致的过程叫 Paxos Instance。
在 Basic Paxos 算法中,主要有两类角色:
Proposer:
- 负责发起提案,提案由提案编号和 value 两部分组成
Acceptor:
负责批准提案。其内部维护三个值:
- minProposal:Acceptor 不接受任何编号小于 minProposal 的提案
- AcceptedProposal:Acceptor 当前接受的最大的提案的编号
- AcceptedValue:Acceptor 当前接受的最大的提案的值

如上图所示,Paxos 分为两个阶段:
Prepare 阶段
Proposer 选择新提案编号 n(提案编号递增,且不重复),然后向所有 Acceptor 广播 Prepare(n) 请求
当 Acceptor 收到 Prepare(n) 请求时:
- 如果 n 大于 minProposal,表明该提案是更(gèng)新的提案,此时 Acceptor 将 minProposal 设置为 n,并返回 (AcceptedProposal,AcceptedValue)或(null,null)
- 否则不回复或回复 error(即 Acceptor 只处理编号大于 minProposal 的 Prepare 请求)
Accept 阶段
等待一段时间后,如果 Proposer 收到大多数 Acceptor 的响应,则会向所有 Acceptor 发送 Accept(N, V)请求,其中 N 的值是 n,V 是所有 Acceptor 返回的 Prepare(n) 响应中最大的 AcceptedProposal 对应的 AcceptedValue,如果所有 Acceptor 都没返回(AcceptedProposal,AcceptedValue),那么 V 由 Proposer 指定
Acceptor 在收到 Accept(N,V)请求时:
- 如果 N 大于等于 minProposal,那么 Acceptor 将 minProposal 和 AcceptedProposal 设置为 N;将 AcceptedValue 设置为 V,然后回复接受
- 否则不回复或回复 error(即 Acceptor 只接受编号不小于 minProposal 的 Accept 请求)
等待一段时间后,如果 Proposer 收到大多数 Acceptor 的响应,则达成一致;否则跳转到 Prepare 阶段的第一步
通过上述流程可知,在并发情况下,Paxos 存在活锁问题:
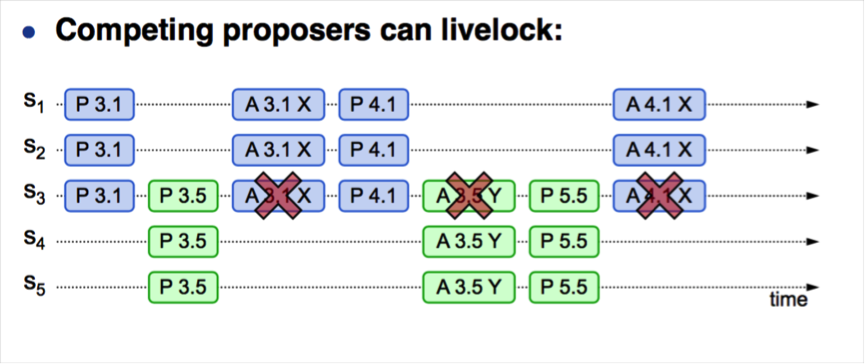
- S1 作为提议者,发起 Prepare(3.1),并在 S1、S2、S3 达成多数派
- S5 作为提议者,发起 Prepare(3.5),并在 S3、S4、S5 达成多数派
- S1 发起 Accept(3.1,value1),由于 S3 上 3.5 > 3.1,导致 Accept 请求无法达成多数派,S1 尝试重新生成提议
- S1 发起 Prepare(4.1),并在 S1、S2、S3 达成多数派
- S5 发起 Accpet(3.5,value5),由于 S3 上提议 4.1 > 3.5,导致 Accept 请求无法达成多数派,S5 尝试重新生成提议
- S5 发起 Prepare(5.5),并在 S3、S4、S5 达成多数派,导致后续 S1 发起的 Accept(4.1,value1)失败
- ......
Paxos 的特点是:每个 Proposer 都可以提出 value,但 Proposer 不会“坚持”自己的 value,而是通过 Prepare 阶段,去“学习”其它 Proposer 提出的 value(图 1 中的第 4 步)。
ZooKeeper 的基本原理
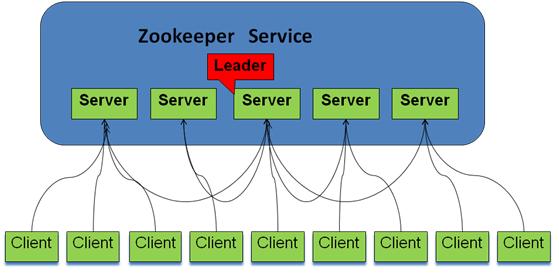
ZooKeeper 集群中的角色主要有以下三类:
| 角色 | 描述 |
|---|---|
| Leader | 负责发起提议;更新系统状态 |
| Follower | 负责接受客户端请求,向客户端返回结果(在收到写请求时 Forward 给 Leader);选举过程中参与投票 |
| Observer | 与 Follower 类似,但在选举过程中不参与投票,只同步 Leader 的状态。Observer 的存在是为了扩展系统,提高读取速度 |
| Client | 请求的发起者 |
系统模型如下所示:
ZooKeeper 的特性:
最终一致性:
- ZooKeeper 提供的一致性是弱一致性,数据的复制有如下规则:ZooKeeper 确保对 ZNode 树的修改被复制到集群中超过半数的节点上。那么就存在某个节点的数据不是最新的,但被客户端访问到的情况。并且会存在一个时间点,集群的状态是不一致的。即 ZooKeeper 只保证最终一致性,实时的一致性由客户端自己通过调用 sync() 方法来保证
原子性:
- 更新只能成功或失败,没有中间状态
顺序性
- 全局有序:如果在 ZooKeeper 集群的某个节点上,事务 a 在事务 b 的前面,那么在集群中的所有节点上,事务 a 都在事务 b 的前面
- 偏序:对于客户端而言,如果事务 a 在事务 b 之前被发布,那么事务 a 必将排在事务 b 的前面
ZooKeeper 的基本概念
- 数据模型
ZooKeeper 的数据模型和 Unix 文件系统很像,都是具有层级关系的树形结构。ZooKeeper 中的每个节点叫 ZNode,ZNode 可以用其路径唯一标识(注意:ZNode 只能使用绝对路径表示,不能使用相对路径表示。除根节点外,路径名不能以 “/” 结尾)。每个 ZNode 可以存储少量数据(默认是1M,可配置。注意:因为 ZooKeeper 在运行时会把 ZNode 加载进内存,所以不建议在 ZNode 上存储大量数据。)。另外,ZNode上还存储 ACL 信息,ZNode 的 ACL 和 Unix 文件系统的 ACL 完全不同,每个 ZNode 的 ACL 互相独立,子节点不会继承父节点的 ACL,关于 ZooKeeper 的 ACL,请参考其它文章。
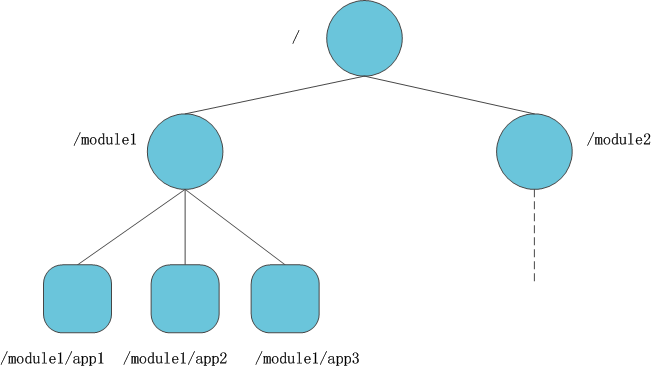
ZNode 的类型:
- 持久化节点:创建之后,需要显式地删除
- 临时节点:创建之后,可以显式地删除;同时,在 Session 结束后,ZooKeeper 会自动地清理该 Session 创建的所有临时节点。临时节点不能有子节点
- 顺序节点:创建顺序节点时,ZooKeeper 会自动地在节点名称后面追加一个递增的序号
下面通过示例,看一下 ZNode 的属性:
xxxxxxxxxx[zk: localhost:2181(CONNECTED) 13] create /test-node test-valueCreated /test-node[zk: localhost:2181(CONNECTED) 14] get -s /test-nodetest-valuecZxid = 0x300000004ctime = Thu Feb 03 16:02:29 CST 2022mZxid = 0x300000004mtime = Thu Feb 03 16:02:29 CST 2022pZxid = 0x300000004cversion = 0dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 10numChildren = 0版本号:
- dataVersion:数据版本号,每次更新节点的数据,dataVersion 都会增加 1
- aclVersion:ACL 的版本号
- cversion:子节点的版本号,当 ZNode 的子节点发生变化时,cversion 会增加 1
下面以数据版本号为例,说明版本号的作用。假设实现 AtomicInteger,该数据类型提供原子的 incr <number> 操作。那么 ZooKeeper Client 的做操可能是:
get -s /AtomicInteger:得到数值 value1 和 版本号 version1set -v <version1> /AtomicInteger <value2>,其中 value2 = value1 + number:- 如果失败,则证明其它客户端已经更新数据,此时客户端需要重试
- 如果成功,则表示成功完成 incr <number> 操作,并且会导致数据版本号增加 1
如果在 set 时,不校验版本号,那么可能导致其它客户端的更新丢失。
事务 ID
- cZxid:创建 ZNode 的事务的 ID
- mZxid:更新 ZNode 的数据的事务的 ID
时间戳
- ctime:ZNode 的创建时间
- mtime:ZNode 的修改时间
接下来介绍 ZooKeeper 的 Watch 特性:
ZooKeeper 支持 Watch 操作,Client 可以在 ZNode 上设置 Watcher(比如 get -w /test-node),当 ZNode 发生相应的变化时,会触发 Watcher,把发生的事件通知给设置 Watcher 的 Client。需要注意的是:Watcher 是一次性的,即触发一次之后,就会被取消,如果想继续 Watch,Client 需要重新设置 Watcher。
ZooKeeper 的客户端 API
使用命令行客户端连接到 ZooKeeper,即可执行命令:
xxxxxxxxxx/path/to/zookeeper_install_directory/bin/zkCli.sh -server your_host:your_portZooKeeper 支持如下命令:
xxxxxxxxxxaddWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVEaddauth scheme authcloseconfig [-c] [-w] [-s]connect host:portcreate [-s] [-e] [-c] [-t ttl] path [data] [acl]delete [-v version] pathdeleteall path [-b batch size]delquota [-n|-b|-N|-B] pathget [-s] [-w] pathgetAcl [-s] pathgetAllChildrenNumber pathgetEphemerals pathhistorylistquota pathls [-s] [-w] [-R] pathprintwatches on|offquitreconfig [-s] [-v version] [[-file path] | [-members serverID=host:port1:port2;port3[,...]*]] | [-add serverId=host:port1:port2;port3[,...]]* [-remove serverId[,...]*]redo cmdnoremovewatches path [-c|-d|-a] [-l]set [-s] [-v version] path datasetAcl [-s] [-v version] [-R] path aclsetquota -n|-b|-N|-B val pathstat [-w] pathsync pathversionwhoami
下面使用一些示例进行说明:
ls /a/znode- 列出 ZNode 的子节点
ls -w /a/znode- 列出 ZNode 的子节点,同时在该 ZNode 上设置 Watcher,当创建或删除子节点时(即发生 NodeChildrenChanged 事件时),会触发 Watcher
get -s /a/znode- 获取 ZNode 上保存的数据及 ZNode 的属性
get -s -w /a/znode- 获取 ZNode 上保存的数据及 ZNode 的属性。同时在该 ZNode 上设置 Watcher,当 set 该 ZNode 时(即发生 NodeDataChanged 事件时),会触发 Watcher
set /a/znode data- 将 ZNode 上的数据设置为 data
set -v <version> /a/znode data- 当 ZNode 的 dataVersion 等于 version 时,将该 ZNode 的数据设置为 data,该命令会导致 dataVersion 增加 1;否则,执行失败
create -e /a/znode data- 创建临时节点 /a/znode,并将其数据设置为 data
create -s /a/znode data- 创建顺序节点,ZooKeeper 会自动地在节点名称后追加一个自增的编号,并将该节点的数据设置为 data
create /a/znode data- 创建持久节点,并将其数据设置为 data
sync /a/znode- 使客户端连接到的 ZooKeeper 实例与 Leader 进行状态同步。sync是异步的,客户端无需等待 sync 调用的返回
ZooKeeper 的应用
1,配置管理
解决多个 Job 实例共享及更新配置的问题
实现方法:
- 将配置内容放到 ZooKeeper 的某个 ZNode 上,比如 /service/common-configuration
- Job 实例启动时,从该 ZNode 上获取配置,并且在该 ZNode 上设置 Watcher
- 当修改该 ZNode 的数据时,ZooKeeper 会通知所有 Job,Job 需要重新从该 ZNode 上获取配置,然后重新设置 Watcher
- 必须处理连接丢失的问题,当发生重连时,需要重新读取数据以及设置 Watcher
2,Leader 选举
Leader 选举的本质是:多个进程“抢”同一个互斥锁,抢到锁的进程成为 Active 进程,没有抢到锁的进程成为 StandBy 进程
实现方法:
每个进程在启动时,都去 ZooKeeper 集群上注册一个临时顺序节点
获取其父节点的所有子节点列表
判断自己是不是序号最小的子节点:
- 如果是,则将 isLeader 标记设为 true
- 如果不是,那么找到比自己次小的节点,然后在该节点上设置 Watcher
主线程判断 isLeader 标记,如其为 true,则表示该进程是 Leader,执行一次 real logic;否则,主线程进入阻塞状态,等待被唤醒,当主线程被唤醒时,重新判断 isLeader 标记,如此反复循环......
当创建次小节点的进程退出时,次小节点会被 ZooKeeper 删除,并且触发该进程在其上设置的 Watcher,此时,事件线程需要获取父节点的所有子节点,并判断该临时节点是不是序号最小的子节点
- 如果是,将 isLeader 标记设置为 true,并 notify 主线程
- 否则,找到次小节点,并在其上设置 Watcher
必须考虑连接丢失的情况,当连接丢失时,需要将 isLeader 设置为 false。重连时,需要删除旧的临时顺序节点,创建新的临时顺序节点,然后重新判断新建的临时顺序节点是不是序号最小的节点
3,命名服务
在分布式系统中,通过使用命名服务,客户端能够通过指定的名字来自动发现资源或服务的地址、提供方等信息
实现方法:
- 服务提供方启动时,在 ZooKeeper 上创建一个临时节点(比如:/service/test_service/ip:port),该操作完成了服务的发布
- 服务消费方在启动时,获取 /service/test_service 的所有的子节点,解析之后,保存到本地 Cache 中,并 Watch 该路径,当该路径的子节点发生变化时,需要重新获取子节点列表;解析;更新本地 Cache;设置 Watcher。服务消费方也可以通过在 ZooKeeper 的某个路径下创建临时节点的方式,来让系统的其它组件知道目前服务的所有消费方的信息
- 必须考虑连接丢失的情况,当重新连接的时候,服务提供方需要删除旧的临时节点,创建新的同名临时节点;服务消费方需要重新设置 Watcher
4,屏障(Barrier)
- 屏障会阻塞所有正在屏障上等待的节点,直到屏障被删除,这些节点才能继续运行
5,双屏障
- 当足够多的节点进入双屏障时,节点才能继续运行;当足够多的节点离开双屏障时,节点才能离开双屏障
6,组员管理
在 Master-Slave 结构的分布式系统中,Master 需要作为“总管”,来管理所有 Slave,当有 Slave 加入,或有 Slave 宕机时,Master 需要感知到,然后作出对应的调整,以便不影响整个集群对外提供服务
实现方法:
- Master 在 ZooKeeper 上创建 /service/slaves 结点,并设置 Watcher
- 每个 Slave 在启动成功后,创建唯一标识自己的临时(Ephemeral)结点 /service/slaves/${slave_id},并将自己地址(ip:port)等相关信息写入该结点
- Master 收到有新结点加入的通知后,做相应的处理
- 如果有 Slave 宕机,由于它所对应的结点是临时结点,在 Session 超时后,ZooKeeper 会自动删除该结点
- Master 收到有结点消失的通知,做相应的处理
7,分布式锁
下面是博主实现的读写锁(互斥锁的实现就是 LeaderElection 的实现)
读锁是共享的,写锁是独占的;当读锁存在时,其它进程的读锁可立即获取到,但是写锁需要等待;当写锁存在时,其它进程的读锁和写锁都需要等待
实现方法:
- 创建临时顺序节点,比如 /lock/test/read-write-lock-
- 如果该节点是序号最小的节点,那么获取锁成功
- 否则,如果是写锁,则 Watch 次小节点,然后线程进入到等待状态;如果是读锁,则 Watch 前一个写锁对应的节点,如果前面不存在写锁,则获取成功,否则线程进入到等待状态
- 当发生 NodeDeleted 事件时,唤醒线程,然后跳转到第 2 步
- 当连接断开时,唤醒线程,使之回到第 2 步,此时可能会抛出连接相关的异常
- 重连时,删除旧 ZNode,创建新的,然后跳转到第 2 步
两阶段提交和 Zab 协议
两阶段提交用来保证分布式事务的原子性,两阶段提交中的角色分为:协调者(1 个)和参与者(多个),其过程如下:
协调者记录 Prepare T 日志,并向所有参与者发送 Prepare T 消息
参与者收到 Prepare T 消息后,在自身执行事务的预处理,此时存在两种情况:
- 如果参与者可以提交事务,那么记录日志,并返回 Ready T
- 如果参与者不能提交事务,那么撤销自身的修改;记录日志;返回 Not Commit T
协调者收集所有参与者返回的意见,此时存在三种情况:
- 如有参与者返回 Not Commit T,那么协调者记录 Abort T 日志,并给所有参与者发送 Abort T 消息。参与者在收到 Abort T 消息后,撤销自身上执行的预操作,记录 Abort T 日志,终止事务的提交
- 如果所有参与者都返回 Ready T,那么协调者记录 Commit T 日志,并给所有参与者发送 Commit T 消息。参与者在收到 Commit T 后,记录 Commit T 日志,提交事务
- 如果协调者迟迟没有收到某个参与者的响应,那么认为该参与者返回 VOTE_ABORT T 消息。 此时协调者记录 VOTE_ABORT T 日志,并向所有参与者发送 VOTE_ABORT T 消息。参与者在收到 VOTE_ABORT T 消息后,撤销自身上执行的预操作,记录 VOTE_ABORT T 日志,终止事务的提交
ZooKeeper Atomic Broadcast(简称 ZAB,Zookeeper 原子消息广播协议)是 ZooKeeper 保证数据一致性的核心算法。它分为两种模式:
恢复模式:
ZooKeeper 集群进入恢复模式的情况如下:
- 集群在启动的过程中
- Leader 服务器出现网络中断、崩溃退出、重启等异常情况
- 网络分区
- Leader 失去大多数 Follower
ZooKeeper集群进入恢复模式后:
- 如果 Leader 出现问题,那么重新选举新 Leader。在选出 Leader,并且集群中过半的机器与 Leader 完成状态同步后,集群会退出恢复模式进入消息广播模式(ZooKeeper 的选举算法有两种:Basic Paxos 和 Fast Paxos(默认))
- 当新节点加入集群时,如果此时已经有 Leader 负责消息广播,那么该节点进入数据恢复模式,它找到 Leader,然后与之进行同步,同步完成后,该节点进入到消息广播模式,参与到消息广播流程中
消息广播模式:
ZAB 的消息广播过程类似于两阶段提交,但是移除了 Abort 逻辑,Follower 要么 ACK Leader 发来的 Proposal,要么不认该 Leader
- Leader 为事务生成全局递增的事务 ID(即 ZXID),保证每个消息的因果顺序
- Leader 为事务生成 Proposal,并进行广播
- Leader 会为每个 Follower 分配单独的队列,之后将需要广播的事务 Proposal 依次放到这些队列中,然后根据 FIFO 策略进行发送(因此所有 Follower 收到的事务序列都相同,可以保证严格的全局有序关系)
- Follower 收到 Leader 发来的 Proposal 后,首先以日志形式写入磁盘,在成功写入之后,给 Leader 发送 ACK 响应
- 当 Leader 收到超过半数的 Follower 的 ACK 响应后,Leader 自身也会完成对事务的提交(记录 Commit 日志,修改内存中的数据),然后广播 Commit 消息给所有 Follower。Follower 在收到 Commit 消息后,会完成事务的提交
ZAB 的崩溃恢复需要保证以下两种情况:
- 已经在 Leader 上提交的事务,最终会被所有服务器接受
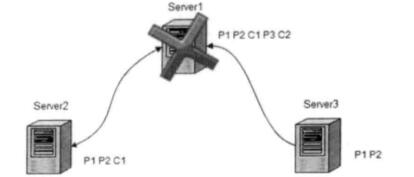
Server1 是 Leader,C2 在 Leader 上完成事务提交,但在通知 Follower 服务器 Commit 时挂掉,保证 C2 在 Server2 和 Server3 上提交
- 丢弃只在 Leader 上被提出的事务
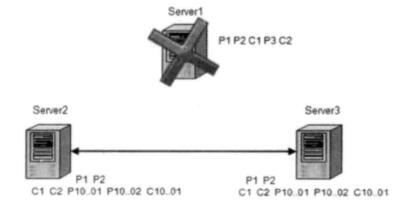
假设初始的 Leader Server1 在提出事务 Proposal3(P3)后,还没有给 Follower 发送请求时宕机,那么丢弃 P3
ZAB 选举算法要求:
- 旧 Leader 宕机后,选举新 Leader,旧 Leader 重启后不能再次成为这次选举的 Leader
- 旧 Leader 宕机后,在剩下的 Follower 中选举新 Leader 的标准是:事务 ID 最大的那个 Follower(即数据最新的 Follower)成为新 Leader
- 事务 ID(即 ZXID)是 64 位的数字。其中低 32 位是单调递增的计数器,高 32 位代表 Leader 从生到死的 Epoch 编号
- 新 Leader 被选举出来后,从事务 Proposal 中分析出旧 Leader 的 Epoch 编号,然后递增 1,作为新事务 ID 的高 32 位,新事务 ID 的低 32 位从 0 重新开始计数
- 新 Leader 通过事务 ID 和所有 Follower 上的事务 ID 进行对比,保证数据在所有 Follower 上与之达成同步。旧 Leader 上新被提出的事务被抛弃。当数据达到同步,才将 Follower 加到可用 Follower 列表。然后开始消息广播