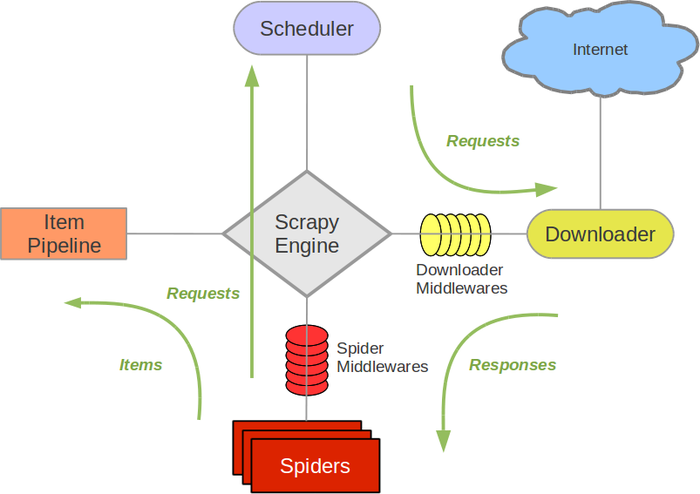
Scrapy的执行流由引擎来控制:
假设读者已经安装好了Scrapy。博主的运行环境是:
1,创建项目:
scrapy startproject myproject
会看到类似下面的输出:
[root@iZj6chejzrsqpclb7miryaZ ~]# scrapy startproject myproject
New Scrapy project 'myproject', using template directory '/usr/lib/python2.7/site-packages/Scrapy-1.5.0-py2.7.egg/scrapy/templates/project', created in:
/root/myproject
You can start your first spider with:
cd myproject
scrapy genspider example example.com
[root@iZj6chejzrsqpclb7miryaZ ~]# cd myproject/
[root@iZj6chejzrsqpclb7miryaZ myproject]# tree .
.
├── myproject
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
2 directories, 7 files
项目目录下包含以下文件:
ITEM_PIPELINES设置PipeLine及其优先级、通过DOWNLOAD_TIMEOUT设置下载器的下载超时时间2,创建Item:
爬取的主要目标就是从非结构化的数据中提取结构化的数据。比如爬取的结果可能是一个网页,而我们要获取的目标是这个网页的标题和正文,此时,我们就需要从网页中将我们想要的内容提取出来,保存到Item中,也就是说,Item其实是保存爬取到的数据的容器。
可以通过创建一个scrapy.Item类,并定义类型为scrapy.Field的类属性,来定义一个Item。值得注意的是:scrapy.Item类提供了额外的保护机制,来避免向其中插入未定义的字段。下面是一个定义Item的例子:
# myproject/items.py
import scrapy
class SinaItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field
3,创建爬虫:
一个爬虫就是一个scrapy.Spider的子类,它定义爬取的动作(比如,是否跟进链接)以及如何从爬取的内容中,提取结构化的数据。
该类有几个重要的属性:
下面是一个爬取新浪科技的一个正文页的爬虫:
# myproject/spiders/sina_crawler.py
import scrapy
from myproject.items import SinaItem
class SinaCrawler(scrapy.Spider):
name = "sina_crawler"
start_urls = ["http://tech.sina.com.cn/t/2018-04-08/doc-ifyvtmxe0886959.shtml"]
def parse(self, response):
item = SinaItem()
item["title"] = response.xpath('//h1[@class="main-title"]/text()').extract()[0]
item["content"] = response.xpath('//div[@id="artibody"]').extract()[0]
return item
4,使用选择器提取数据:
Scrapy中提取数据的机制,叫选择器(selector)。它构建在lxml库之上,因此它支持通过xpath和css表达式来“选择”HTML的某个部分。
如上面的例子中的红色部分所示,可以通过Response对象的xpath()或css()方法,来获取一个SelectorList对象(其中包含多个Selector对象),再通过SelectorList对象的extract()方法,提取数据。
5,保存爬取到的数据:
Item在Spider中被收集之后,会被传给Item PipeLine,多个Item PipeLine会按照一定的顺序对Item进行处理,比如:
等。
每个Item PipeLine都是一个Python类,它需要实现以下方法:
process_item(item, spider):open_spider(spider):close_spider(spider):下面是一个将Item保存到json文件的PipeLine的例子:
# myproject/pipelines.py
import json
class JsonWriterPipeLine(object):
def process_item(self, item, spider):
with open("result.json", "wb") as fd:
fd.write(json.dumps(dict(item), indent=4) + "\n")
yield item
在定义了PipeLine之后,需要在settings.py中启用它:
ITEM_PIPELINES = {
'myproject.pipelines.JsonWriterPipeLine': 300,
}
item会按照数字从低到高的顺序通过PipeLine,通常将这些数字定义在0-1000
6,启动爬虫:
在项目目录下,执行:
scrapy crawl sina_crawler
会看到,Item被保存到result.json文件中了
Scrapy的执行流由引擎来控制:
该类用于执行一次爬取,主要代码如下:
class Crawler(object):
def __init__(self, spidercls, settings=None):
# 参数spidercls:Spider类
# 参数settings:项目用到的设置
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.spidercls = spidercls
self.settings = settings.copy()
# 使用Spider类的custom_settings更新settings
self.spidercls.update_settings(self.settings)
...
# 是否正在抓取
self.crawling = False
# Spider类的对象
self.spider = None
# 引擎对象,负责控制整个执行流
self.engine = None
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
# 如果正在抓取,那么抛出异常
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 使用该Crawler对象创建一个Spider类对象,会将Crawler对象的settings设置为Spider对象的settings
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎对象
self.engine = self._create_engine()
start_requests = iter(self.spider.start_requests())
# 启动引擎对象
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
# In Python 2 reraising an exception after yield discards
# the original traceback (see https://bugs.python.org/issue7563),
# so sys.exc_info() workaround is used.
# This workaround also works in Python 3, but it is not needed,
# and it is slower, so in Python 3 we use native `raise`.
if six.PY2:
exc_info = sys.exc_info()
# 出现异常时,关闭爬取和引擎,并重新抛出异常
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise
def _create_spider(self, *args, **kwargs):
return self.spidercls.from_crawler(self, *args, **kwargs)
def _create_engine(self):
# 当Spider对象空闲时,会执行self.stop()方法,
# 而在self.stop()中,会执行引擎对象的stop()方法,
# 也就是说:当爬取完毕时,会关闭引擎
return ExecutionEngine(self, lambda _: self.stop())
@defer.inlineCallbacks
def stop(self):
if self.crawling:
self.crawling = False
yield defer.maybeDeferred(self.engine.stop)
下面看一个直接使用Crawler类的例子:
# test_crawler.py
import sys
sys.path.append("myproject")
sys.path.append("myproject/spiders")
from scrapy.crawler import Crawler
from scrapy.settings import Settings
from twisted.internet import reactor
from sina_crawler import SinaCrawler
import settings as mysettings
def stop(_):
print "reactor.stop()"
reactor.stop()
def main():
settings = Settings()
settings.setmodule(mysettings)
crawler = Crawler(SinaCrawler, settings)
d = crawler.crawl()
d.addBoth(stop)
reactor.run()
if __name__ == "__main__":
main()
可以通过调用CrawlerRunner对象的crawl()方法【创建Crawler对象,并开启爬取】。然后通过调用join()方法等待,直到所有的Crawler对象都爬取完毕。
主要代码如下:
class CrawlerRunner(object):
def __init__(self, settings=None):
# 参数settings:项目用到的设置
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.settings = settings
# SpiderLoader对象负责根据爬虫名称,加载Spider类
self.spider_loader = _get_spider_loader(settings)
# self._crawlers用于保存所有的Crawler对象
self._crawlers = set()
# self._active用于保存调用Crawler.crawl()方法,返回的defer对象
self._active = set()
def _create_crawler(self, spidercls):
# 如果spidercls是爬虫名称,那么使用SpiderLoader对象,加载其对应的Spider类
if isinstance(spidercls, six.string_types):
spidercls = self.spider_loader.load(spidercls)
# 使用Spider类和settings,创建Crawler对象,并返回
return Crawler(spidercls, self.settings)
def create_crawler(self, crawler_or_spidercls):
# 该方法会返回一个Crawler对象
# 参数crawler_or_spidercls:可以是Crawler对象,也可以是Spider类,还可以是爬虫名称
if isinstance(crawler_or_spidercls, Crawler):
return crawler_or_spidercls
return self._create_crawler(crawler_or_spidercls)
# 创建一个Crawler对象,并且调用它的crawl()方法开始爬取
def crawl(self, crawler_or_spidercls, *args, **kwargs):
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
def _crawl(self, crawler, *args, **kwargs):
self.crawlers.add(crawler)
d = crawler.crawl(*args, **kwargs)
self._active.add(d)
def _done(result):
self.crawlers.discard(crawler)
self._active.discard(d)
return result
return d.addBoth(_done)
def stop(self):
# 并发的关闭所有的Crawler对象
return defer.DeferredList([c.stop() for c in list(self.crawlers)])
@defer.inlineCallbacks
def join(self):
# 该方法返回一个defer对象,当所有被添加到该CrawlerRunner对象的Crawler对象都完成时,返回的defer对象,才会完成
while self._active:
yield defer.DeferredList(self._active)
下面看一个直接使用CrawlerRunner的例子:
# test_crawler_runner.py
import sys
sys.path.append("myproject")
sys.path.append("myproject/spiders")
from scrapy.crawler import CrawlerRunner
from scrapy.settings import Settings
from twisted.internet import reactor, defer
from sina_crawler import SinaCrawler
import settings as mysettings
def stop(_):
print "reactor.stop()"
reactor.stop()
@defer.inlineCallbacks
def crawl():
settings = Settings()
settings.setmodule(mysettings)
crawler_runner = CrawlerRunner(settings)
crawler_runner.crawl(SinaCrawler)
yield crawler_runner.join()
yield crawler_runner.stop()
d = crawl()
d.addBoth(stop)
if __name__ == "__main__":
reactor.run()
CrawlerProcess类用于在一个进程中,并发地运行多个Crawler实例。该类继承自CrawlerRunner,添加了启动twisted reactor 和 处理关闭信号的支持。
主要代码如下:
class CrawlerProcess(CrawlerRunner):
def __init__(self, settings=None, install_root_handler=True):
super(CrawlerProcess, self).__init__(settings)
# 将self._signal_shutdown()安装为所有通用的关闭信号(比如SIGINT、SIGTERM等)的处理函数
install_shutdown_handlers(self._signal_shutdown)
...
# 第一次收到关闭信号时,尝试优雅地关闭reactor,也就是在关闭reactor之前,先关闭所有的Crawler实例
def _signal_shutdown(self, signum, _):
install_shutdown_handlers(self._signal_kill)
signame = signal_names[signum]
logger.info("Received %(signame)s, shutting down gracefully. Send again to force ",
{'signame': signame})
reactor.callFromThread(self._graceful_stop_reactor)
# 再次收到关闭信号时,直接关闭reactor
def _signal_kill(self, signum, _):
install_shutdown_handlers(signal.SIG_IGN)
signame = signal_names[signum]
logger.info('Received %(signame)s twice, forcing unclean shutdown',
{'signame': signame})
reactor.callFromThread(self._stop_reactor)
# 在关闭所有的Crawler实例之后,再关闭reactor
def _graceful_stop_reactor(self):
d = self.stop()
d.addBoth(self._stop_reactor)
return d
# 直接关闭reactor
def _stop_reactor(self, _=None):
try:
reactor.stop()
except RuntimeError: # raised if already stopped or in shutdown stage
pass
def start(self, stop_after_crawl=True):
# 如果参数stop_after_crawl为True,那么在所有Crawler实例都抓取完成后,停止reactor
if stop_after_crawl:
d = self.join()
# Don't start the reactor if the deferreds are already fired
if d.called:
return
d.addBoth(self._stop_reactor)
reactor.installResolver(self._get_dns_resolver())
tp = reactor.getThreadPool()
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
# 启动reactor
reactor.run(installSignalHandlers=False) # blocking call
下面看一个直接使用CrawlerProcess的例子:
# test_crawler_process.py
import sys
sys.path.append("myproject")
sys.path.append("myproject/spiders")
from scrapy.crawler import CrawlerProcess
from scrapy.settings import Settings
from sina_crawler import SinaCrawler
import settings as mysettings
def crawl():
settings = Settings()
settings.setmodule(mysettings)
crawler_process = CrawlerProcess(settings, install_root_handler=False)
crawler_process.crawl(SinaCrawler)
crawler_process.start(stop_after_crawl=True)
if __name__ == "__main__":
crawl()
其实,命令:
scrapy crawl <spider_name>
本质上就是执行了:
... crawler_process.crawl(<spider_name>) crawler_process.start()
Scrapy是基于Twisted开发的,因此开发人员需要对异步编程和Twisted网络库有一定的了解。本文后续也可能会补充一些Twsited基础。
本文主要是针对应用层组件的源码进行了一些解析。关于Scrapy中的ExecutionEngine、Scraper、Scheduler、Downloader等基础组件,因其执行流程基本和Scrapy架构概览中所描述的一样,所有未做解析。
关于Scrapy的入门,参考文档中的教程就不错;关于xpath的入门,可以移步http://www.w3school.com.cn/xpath/。