概述
本文将介绍如何在 Python 中使用多进程、多线程、协程进行并发编程。
并发和并行
在介绍高并发之前,需要先了解两个概念:
并发
程序中存在一个或多个执行流,但是在某一时刻,只有一个执行流能够执行
并行
程序中存在一个或多个执行流,在某一时刻,多个执行流可以同时执行
下图是 Erlang 之父 Joe Armstrong 对并发与并行的区别的解释:

即:并发是两个队列交替使用一台咖啡机,并行是两个队列同时使用两台咖啡机。
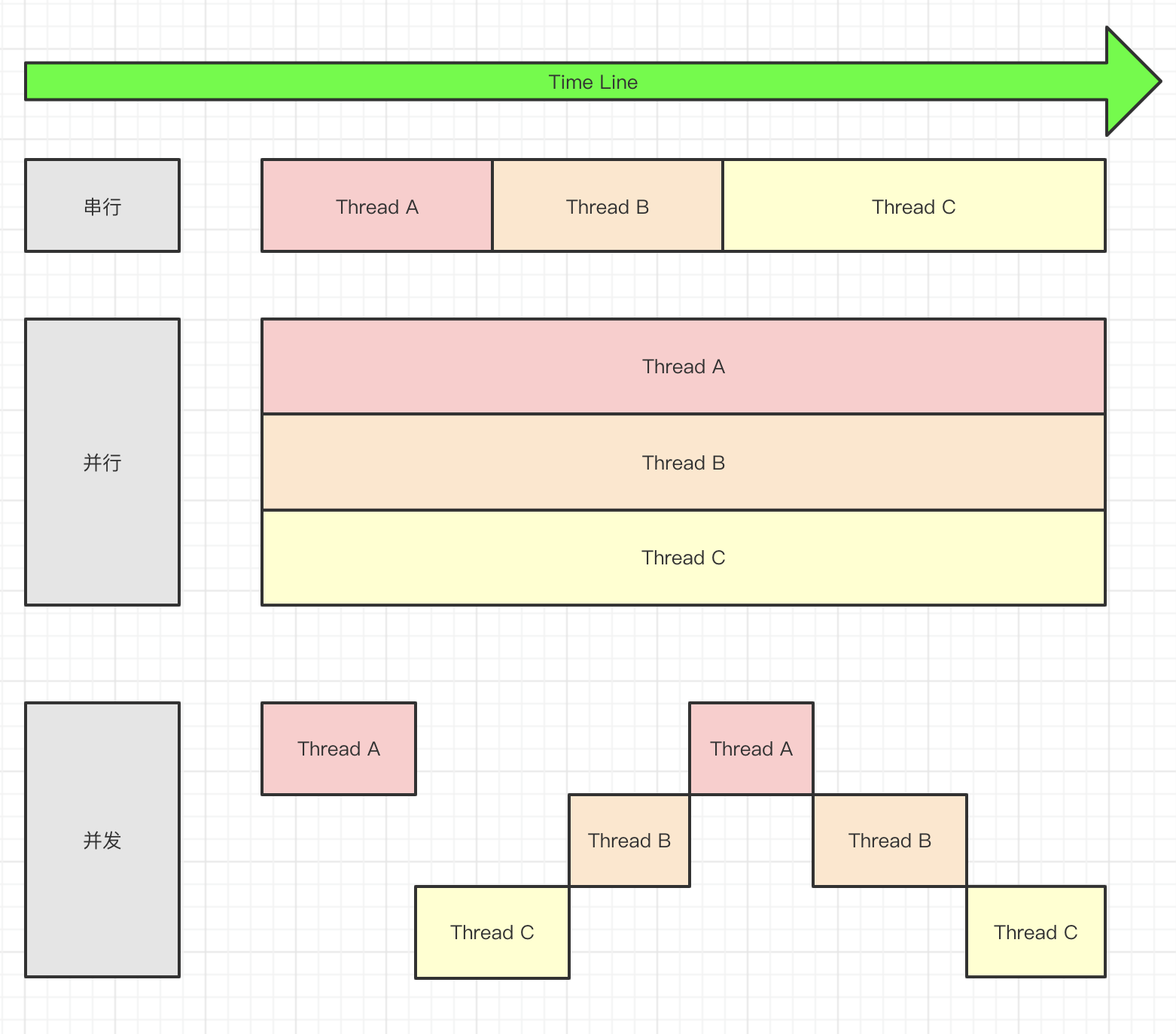
下图是博主对串行、并发、并行的理解:
{kind=link}
GIL
在介绍 Python 并发编程之前,需要先了解一个非常重要的概念:GIL。GIL 的全称是 Global Interpreter Lock,即全局解释器锁。需要特别强调的是:GIL 是 CPython 中的术语,而非 Python 语言的特性。除 CPython 外,Python 语言还有许多其它实现,比如 PyPy、Jython、IronPython 等。CPython 是官方实现的解释器,支持 Python 语言的全部特性,因此它是使用最广泛的 Python 解释器。
CPython 中的每个线程在执行之前都需要先获取到 GIL,以阻止其它线程执行。CPython 引进 GIL 的原因与其底层内存管理有关:
在下面的例子中:
>>> import sys>>> a = []>>> b = a>>> sys.getrefcount(a)3空列表([])的引用计数为 3,因为 a、b 引用了它,并且它被当作参数传递给函数 getrefcount()。
在没有 GIL 的情况下,假设有两个线程同时引用该列表,双方都尝试操作它,很可能造成引用计数的条件竞争(race condition),导致引用计数只增加 1(实际应该增加 2),当第一个线程结束时,会将引用计数减少 1,此时该列表的引用计数为 0,会被回收掉,当第二个线程再次试图访问它时,将无法找到有效的内存。
因此,CPython 引进 GIL 可以最大程度地规避内存管理等复杂的竞态条件问题。
关于 Python 的垃圾回收机制,请参考:http://timd.cn/python/gc/
如果一个线程在开始执行时锁住 GIL,但永不释放,那么其它线程将无法执行。CPython 的间隔性检查(check interval)机制可以避免该问题发生,即:线程会计算其已执行的字节码(opcode)数量,如果达到阈值就释放 GIL,给其它线程执行的机会。设置和查看该阈值的方式如下:
xxxxxxxxxx>>> import sys>>> sys.getcheckinterval()100>>> sys.setcheckinterval(50)>>> sys.getcheckinterval()50间隔性检查的实现如下:
xxxxxxxxxxfor (;;) { if (--ticker < 0) { ticker = check_interval; /* Give another thread a chance */ PyThread_release_lock(interpreter_lock); /* Other threads may run now */ PyThread_acquire_lock(interpreter_lock, 1); } bytecode = *next_instr++; switch (bytecode) { /* execute the next instruction ... */ }}可见 Python 线程在执行前会先检查 ticker 计数,只有在 ticker 大于 0 的情况下,才会执行自己的字节码。
除此之外,线程在等待 IO、执行 C 扩展时,也会释放 GIL。因此 Python 的多线程对 IO bound 程序比较友好,当至少有一个 CPU bound 的线程存在时,那么整体效率会因 GIL 而大幅下降。对于 CPU bound 程序,应该尽量:
- 使用多进程代替多线程
- 将核心部分写成 C 扩展
最后再分析两个问题:
Q:既然存在 GIL,是否意味着 Python 开发人员可以无视线程安全问题呢?
A:不可以,虽然 GIL 保证在同一时刻,只有一个线程能够执行,但是线程还有 check interval 这样的抢占机制。
Q:CPython 是否在考虑去 GIL?
A:Guido 曾经说过,去 GIL 很困难。虽然 CPython 因为内存管理而引入 GIL,但是因为 GIL 的存在,许多其它特性也开始依赖它,所以去 GIL 很困难,但是 Python 社区在不断地改进 GIL。
进程、线程、协程的区别
进程和线程的区别如下:
- 进程是操作系统进行资源分配的基本单位;线程是处理器调度和分配的基本单位
- 进程是线程的“容器”,一个进程可以有一个或多个线程,它们共享进程的地址空间(包括代码段、数据段、堆等)和一些进程级的资源(比如文件描述符等)
- 进程上下文切换开销大,不需要频繁地切换;线程只有少量资源,上下文切换开销小,会被频繁地调度和切换
1,关于进程的地址空间布局,可参考:http://blog.timd.cn/runtime-based-on-stack/
2,每个线程都有自己的用户栈和内核栈
线程的实现方式有三种:
使用内核线程实现
内核线程(Kernel-Level Thread,KLT)是内核支持的线程,这种线程由内核切换,内核通过操纵调度器对线程进行调度,并负责将线程的任务映射到各个处理器上。每个内核线程可被视为内核的一个“分身”,这种操作系统有能力同时处理多件事情,支持多线程的内核叫做多线程内核。
程序一般不会直接使用内核线程,而是使用内核线程的一种高级接口:轻量级进程(Light Weight Process,LWP),每个轻量级进程都由一个内核线程支持。这种轻量级进程与内核线程之间 1:1 的关系称为一对一的线程模型。
使用用户线程实现
用户线程(User Thread,UT)完全建立在用户空间的线程库上,内核感知不到线程的存在。用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助。这种进程与用户线程之间 1:N 的关系称为一对多的线程模型。
使用用户线程 + 轻量级进程混合实现
在混合实现下,既存在用户线程,又存在轻量级进程。用户线程还是完全建立在用户空间中,用户线程的创建、切换、析构等操作依然廉价。轻量级进程则作为用户线程与内核线程之间的桥梁,这样可以使用内核提供的线程调度及处理器映射,并且用户线程的系统调用通过轻量级进程来完成,大大降低了整个系统被完全阻塞的风险。在混合模式中,用户线程与轻量级进程的数量比不定,即为 N:M 的关系。
原创声明:线程实现方式的原文地址是 https://www.cnblogs.com/lixiaochao/p/9490264.html。
可以看出协程(coroutine)本质上就是用户线程,它与线程的区别如下:
- Python 线程会被映射到操作系统的原生线程上,而 Linux 的线程是轻量级进程,故线程的创建、切换和销毁开销较大;而协程是在用户空间模拟出的执行流,创建、切换和销毁开销很小
- 协程与线程都有自己的调用栈,协程的调用栈是在用户空间模拟出来的
- 多线程程序是多个线程并行执行,即在某个时刻,可能有多个执行流同时在执行(Python 是伪并行);而协程强调的是多个协程之间协同合作,只有当正在执行的协程主动放弃执行权,其它协程才有机会获得执行权,即系统中可能存在多个执行流,但在某一时刻,只有一个执行流在执行
关于 Tornado 的协程实现,可参考:http://timd.cn/tornado/gen/
多进程编程
1,使用 multiprocessing 包
关于 multiprocessing 包,可参考:http://timd.cn/python/multiprocessing/
2,使用 os.fork() 函数
os.fork() 用于“分叉”出一个子进程。该函数在子进程中返回 0,在父进程中返回子进程的 PID,如果发生错误,抛出 OSError。
下面是一个简单的例子:
x
import osimport timedef main(): pid = os.fork() if pid == 0: time.sleep(3) print(f"this is child, pid is {os.getpid()}") # exit code is 3 os._exit(3) elif pid > 0: print(f"this is parant, child pid is {pid}") print(os.waitpid(pid, 0)) else: raise SystemError("fork failure")if __name__ == "__main__": main()3,使用 os.exec* 系列函数
请先阅读官方文档,获取 Python 支持的 os.execv* 系列函数。
这些函数执行新程序,并且替换当前进程,他们不返回。在 Unix 中,新的可执行程序被加载进当前进程,并且拥有与调用方相同的 PID。如果发生错误抛出 OSError。
当前进程会被立即替换,不会刷新已经打开的文件对象和描述符,因此在这些文件描述符上可能存在缓冲的数据,因此在调用 exec* 之前应该使用 sys.stdout.flush() 或 os.fsync() 刷新它们。
下面是一个简单的例子:
xxxxxxxxxximport osimport timedef main(): print(f"my pid is {os.getpid()}") os.execv( "/usr/local/bin/python", [ "python", "-c", "import os; print(f'hello, my pid is {os.getpid()}')" ] ) print(f"unreachable here")if __name__ == "__main__": main()可见,fork() 是“分身”;exec* 是“变身”。
4,使用 subprocess 包
请先阅读官方文档,下面看一个简单的例子:
xxxxxxxxxximport subprocessdef main(): p = subprocess.Popen( """ python -c 'import sys; print(f"stdin is {sys.stdin.read()}")' """, shell=True, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, ) stdout_data, stderr_data = p.communicate(b"input data") print(f"exit code is {p.returncode}, " f"stdout data is {stdout_data}, " f"stderr data is {stderr_data}")if __name__ == "__main__": main()5,等等
多线程编程
threading
各种同步原语
concurrent 包
进程池
线程池
协程编程(Python 3.6+)
1,关于 IO 多路复用,可参考:http://timd.cn/io-multiplex/
2,关于 Tornado 的 IOLoop ,可参考:http://timd.cn/tornado/ioloop/
tornado
asyncio
异步网络库
同步原语