LeRobotDataset v3.0 基础
LeRobotDataset v3.0 是机器人学习数据的标准格式。它提供对多模态时序数据、传感运动信号、多摄像头视频的统一访问,以及用于在 Hugging Face 上索引、搜索、可视化的丰富元数据。
该文档讲述:
- 理解
v3.0设计及目录布局
- 使用
LeRobotDataset加载数据集
- 使用
StreamingLeRobotDataset流式访问数据集,且无需下载
- 在训练期间应用图像变换进行数据增强
1. v3 的特性
- 基于文件的存储:每个 Parquet/MP4 文件可包含多个 Episode(在
v2中每个 Episode 使用一个文件)。
- 关系型元数据:通过元数据而非文件名解析 Episode 边界与查询。
- 更低的文件系统压力:文件更少但更大 => 初始化更快,且在大规模场景下问题更少。
- 统一的组织方式:数据与视频使用一致的目录布局。
2. 安装
LeRobotDataset v3.0 包含在 lerobot >= 0.4.0 版本中。
3. 格式设计
v3 的一个核心原则是将存储与用户 API 解耦:以高效方式存储数据(少量大文件),而对外 API 提供直观的 Episode 级访问。
v3 有三大支柱:
- 表格数据:低维、高频信号(状态、动作、时间戳)存储在 Apache Parquet 中;可通过
datasets栈进行内存映射或流式访问。
- 视觉数据:相机帧被拼接、编码为 MP4;同一 Episode 的帧将被分组;视频按相机分片以保持实用文件大小。
- 元数据:以 JSON/Parquet 记录描述模式(特征名、数据类型、形状)、帧率、归一化统计,以及 Episode 分段(在共享 Parquet/MP4 文件中的起止偏移)。
为支持扩展到数百万 Episode,多个 Episode 的表格行和视频帧将被拼接到更大的文件中。
每个 Episode 的视图通过元数据重建,而非依赖文件边界。
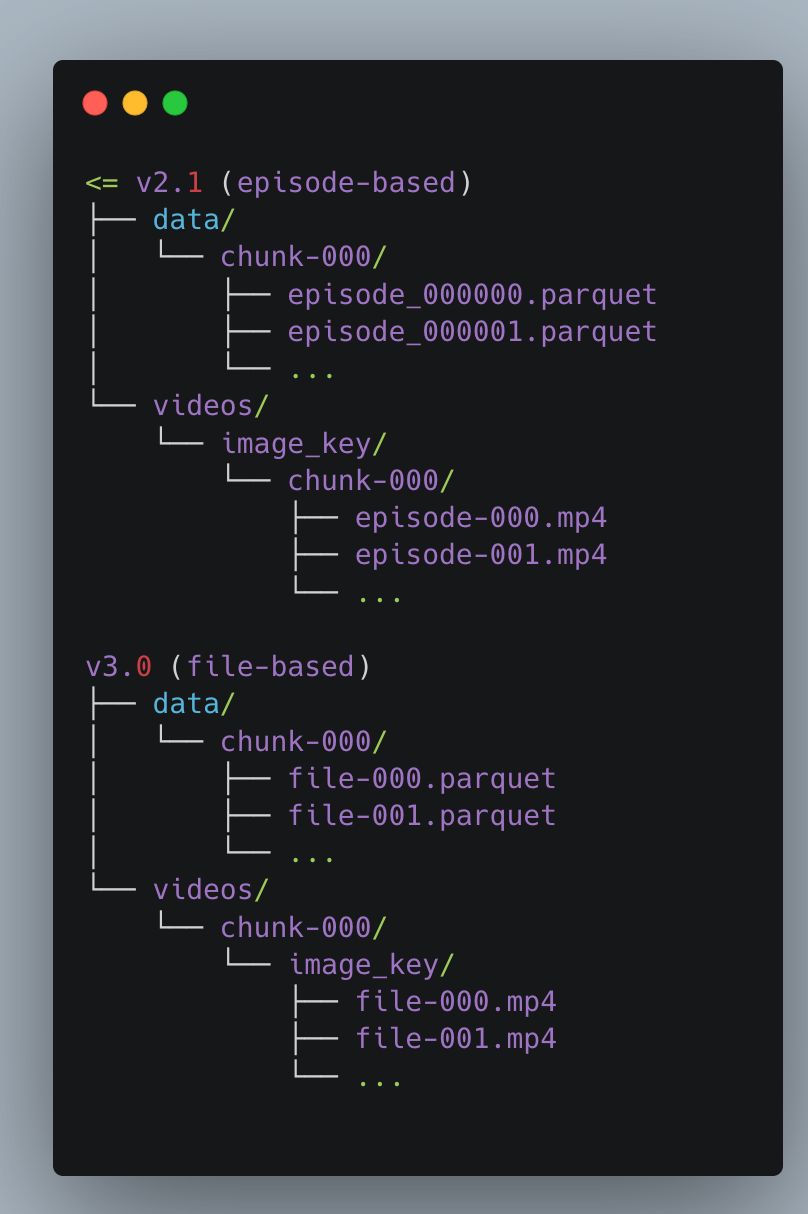
3.1. 目录布局(简化版)
meta/info.json:规范化模式(特征、形状/数据类型)、FPS、代码库版本,以及用于定位数据/视频分片的路径模板。
meta/stats.json:用于归一化的全局特征统计(mean/std/min/max);在代码中可通过dataset.meta.stats访问。
meta/tasks.jsonl:自然语言任务描述与整数 ID 的映射,用于基于任务条件的策略。
meta/episodes/:按 Episode 存储的记录(长度、任务、偏移),为扩展性采用分块 Parquet。
data/:按帧存储的 Parquet 分片;每个文件通常包含多个 Episode。
videos/:按相机存储的 MP4 分片;每个文件通常包含多个 Episode。
4. 加载数据集
4.1. 实例 1 - 读取数据集
import torch
from pathlib import Path
from PIL import Image
from lerobot.datasets.lerobot_dataset import LeRobotDataset
# 用户获取数据集的 Repo ID
repo_id = "lerobot/libero"
# 数据集将被下载及存储到的本地目录。
# 如果设置,所有数据集文件都将直接存储在该路径下。
# 如果未设置,数据集文件将存储在 $HF_LEROBOT_HOME/repo_id 下(通过 HF_LEROBOT_HOME 环境变量配置)
root = "/Users/timchow/Desktop/libero"
# 1) 加载数据集
dataset = LeRobotDataset(repo_id, root=root)
# 2) 通过索引随机访问
sample = dataset[100]
print(sample)
# {
# 'observation.images.image': tensor([C, H, W]),
# 'observation.images.image2': tensor([C, H, W]),
# 'observation.state': tensor([...]),
# 'action': tensor([...]),
# 'timestamp': tensor(1.234),
# 'frame_index': tensor(100),
# 'episode_index': tensor(0),
# 'index': tensor(100),
# 'task_index': tensor(0),
# 'task': 'put the white mug on the left plate ...'
# }
# 3) 将 Images 从 [0, 1] 范围恢复为 [0, 255]
output_dir = Path("saved_images")
output_dir.mkdir(parents=True, exist_ok=True)
image_keys = [
key for key in sample.keys()
if key.startswith("observation.images.")
]
if not image_keys:
raise ValueError("Sample 中未找到图像键(observation.images.*)")
for key in image_keys:
img = sample[key]
if not isinstance(img, torch.Tensor):
continue
if img.ndim != 3:
continue
img_u8 = (img * 255.0).clamp(0, 255).to(torch.uint8)
img_hwc = img_u8.permute(1, 2, 0).cpu().numpy()
safe_name = key.replace(".", "_")
save_path = output_dir / f"{safe_name}.png"
Image.fromarray(img_hwc).save(save_path)
print(f"Saved: {save_path}")
# 4) 通过 delta_timestamps 划分时间窗口(相对于时间点 t 的秒数)
delta_timestamps = {
# 当前帧之前的 0.2s 和 0.1s
"observation.images.image": [-0.2, -0.1, 0.0]
}
dataset = LeRobotDataset(repo_id, root=root, delta_timestamps=delta_timestamps)
# 现在访问索引将为指定的键返回一个栈结构。
sample = dataset[100]
print(sample["observation.images.image"].shape) # [T, C, H, W], where T=3
# 5) 使用 DataLoader 封装
batch_size = 16
data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size)
device = "cuda" if torch.cuda.is_available() else "cpu"
for batch in data_loader:
observations = batch["observation.state"].to(device)
actions = batch["action"].to(device)
images = batch["observation.images.image"].to(device)
# model.forward(batch)
break4.2. 示例 2 - 创建新数据集
from pathlib import Path
import shutil
from lerobot.datasets.lerobot_dataset import LeRobotDataset
from lerobot.datasets.utils import DEFAULT_FEATURES
def build_writable_frame(
raw_frame: dict, feature_keys: list[str], episode_task: str
) -> dict:
"""Convert __getitem__ style sample to add_frame compatible frame."""
writable_keys = [k for k in feature_keys if k not in DEFAULT_FEATURES]
frame = {k: raw_frame[k] for k in writable_keys if k in raw_frame}
# add_frame expects image features in HWC; __getitem__ usually returns CHW.
for key, value in frame.items():
if not key.startswith("observation.images."):
continue
shape = tuple(value.shape)
if len(shape) == 3 and shape[0] in (1, 3) and shape[-1] not in (1, 3):
if hasattr(value, "permute"):
frame[key] = value.permute(1, 2, 0)
elif hasattr(value, "transpose"):
frame[key] = value.transpose(1, 2, 0)
# add_frame requires a "task" field even though it's not in features.
frame["task"] = episode_task
return frame
def main() -> None:
# 1) 加载已有数据集(只为复用 feature/fps/robot_type 配置)
repo_id = "lerobot/libero"
root = "/Users/timchow/Desktop/libero"
dataset = LeRobotDataset(repo_id, root=root)
# 2) 从头创建新数据集
write_fps = int(round(float(dataset.fps)))
print(f"write_fps={write_fps}")
new_repo_id = "new_dataset"
new_root = Path("new_dataset")
if new_root.exists():
shutil.rmtree(new_root)
new_dataset = LeRobotDataset.create(
repo_id=new_repo_id,
root=new_root,
fps=write_fps,
features=dataset.features,
robot_type=dataset.meta.robot_type,
)
# 3) 向新数据集写入 Episode。
# 规则:
# - 每一帧调用一次 add_frame()
# - Episode 结束时调用一次 save_episode()
# - 所有 Episode 写完后调用 finalize()
num_episodes_to_write = 2
frames_per_episode = 128
for ep_idx in range(num_episodes_to_write):
# Use the task of this source episode (from first frame of episode).
ep_start_idx = ep_idx * frames_per_episode
ep_head = dataset[ep_start_idx]
episode_task = ep_head["task"]
print(f"episode_task[{ep_idx}]: {episode_task}")
for t in range(frames_per_episode):
# 下面只是示例:从旧数据集取样本作为 Frame。
# 实际使用时,将 Frame 替换成实时采集/离线读取到的字典(Key 需匹配 features)
src_idx = ep_idx * frames_per_episode + t
raw_frame = dataset[src_idx]
frame = build_writable_frame(
raw_frame, list(new_dataset.features.keys()),
episode_task=episode_task
)
new_dataset.add_frame(frame)
# 必须在每个 Episode 结束时调用。
# macOS 下禁用并行编码,避免 BrokenProcessPool。
new_dataset.save_episode(parallel_encoding=False)
print(f"episode {ep_idx} saved")
# 4) 所有 Episode 写入完成后,必须调用 finalize()
new_dataset.finalize()
print("new dataset finalized")
if __name__ == "__main__":
main()5. 流式读取数据集(无需下载)
使用 StreamingLeRobotDataset 可直接从 Hub 迭代数据。这样可以在不将大型数据集下载到磁盘或加载到内存的情况下进行流式读取,这是新数据集格式的一项关键特性。
from lerobot.datasets.streaming_dataset import StreamingLeRobotDataset
repo_id = "yaak-ai/L2D-v3"
dataset = StreamingLeRobotDataset(repo_id) # streams directly from the Hub6. 图像变换
图像变换是在训练过程中应用于相机帧的数据增强,用于提升模型的鲁棒性和泛化能力。LeRobot 支持多种变换,包括亮度、对比度、饱和度、色相和锐度调整。
6.1. 创建数据集时使用变换
当前仅在训练期间应用变换。当创建数据集时,将在不做变换的情况下保存原始图像。这样可以在后续尝试不同的数据增强,而无需重新录制数据。
6.2. 向已有数据集添加变换
加载数据集时,使用 image_transforms 参数:
from lerobot.datasets.lerobot_dataset import LeRobotDataset
from lerobot.datasets.transforms import ImageTransforms, ImageTransformsConfig, ImageTransformConfig
# Option 1: Use default transform configuration (disabled by default)
transforms_config = ImageTransformsConfig(
enable=True, # Enable transforms
max_num_transforms=3, # Apply up to 3 transforms per frame
random_order=False, # Apply in standard order
)
transforms = ImageTransforms(transforms_config)
dataset = LeRobotDataset(
repo_id="your-username/your-dataset",
image_transforms=transforms
)
# Option 2: Create custom transform configuration
custom_transforms_config = ImageTransformsConfig(
enable=True,
max_num_transforms=2,
random_order=True,
tfs={
"brightness": ImageTransformConfig(
weight=1.0,
type="ColorJitter",
kwargs={"brightness": (0.7, 1.3)} # Adjust brightness range
),
"contrast": ImageTransformConfig(
weight=2.0, # Higher weight = more likely to be selected
type="ColorJitter",
kwargs={"contrast": (0.8, 1.2)}
),
"sharpness": ImageTransformConfig(
weight=0.5, # Lower weight = less likely to be selected
type="SharpnessJitter",
kwargs={"sharpness": (0.3, 2.0)}
),
}
)
dataset = LeRobotDataset(
repo_id="your-username/your-dataset",
image_transforms=ImageTransforms(custom_transforms_config)
)
# Option 3: Use pure torchvision transforms
from torchvision.transforms import v2
torchvision_transforms = v2.Compose([
v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
v2.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
])
dataset = LeRobotDataset(
repo_id="your-username/your-dataset",
image_transforms=torchvision_transforms
)6.3. 可用的变换类型
LeRobot 提供若干变换类型:
- ColorJitter:调整亮度、对比度、饱和度和色相
- SharpnessJitter:随机调整图像锐度
- Identity:不进行任何变换(适用于测试)
也可以将任何 torchvision.transforms.v2 变换直接传给 image_transforms 参数。
6.4. 配置选项
enable:启用/禁用变换(默认:False)
max_num_transforms:每帧最多应用的变换数量(默认:3)
random_order:按随机 vs. 标准顺序应用变换(默认:False)
weight:每种变换的采样概率(值越高越容易被选中;如果权重总和不为1,将自动归一化)
kwargs:各变换专属参数(比如亮度范围)
6.5. 可视化变换
使用可视化脚本预览变换对数据的影响:
lerobot-imgtransform-viz \
--repo-id=your-username/your-dataset \
--output-dir=./transform_examples \
--n-examples=5这将保存展示各个变换效果的示例图像,帮助调节参数。
6.6. 最佳实践
- 从保守设置开始:先用较小范围(比如亮度
0.9-1.1),再逐步增大
- 先做可视化测试:使用可视化脚本确认变换效果看起来合理
- 监控训练过程:增强过强、过激进时,可能损害性能
- 贴合应用场景:如果机器人在光照变化环境中运行,可使用亮度/对比度变换
- 合理组合变换:同时使用过多变换可能导致训练不稳定