目录
设定 {n} 匹配长度为n的任意子串;{m, n}匹配长度为m到n的任意子串(m < n)。
对于带有通配符{n}的模式串:
{1}ATC{2}TC{1}ATC
将其按照通配符分割成三个模式子串:ATC、TC、ATC。
然后使用这三个模式子串构造AC自动机。
每个模式子串的末尾字符记录该字符(及其fail指针指向的字符)在原模式串中的位置。
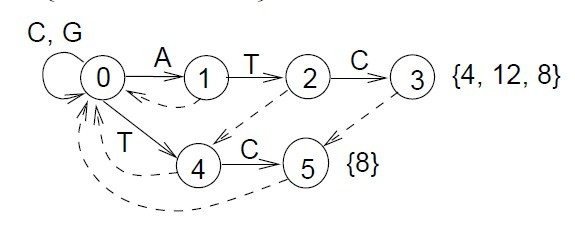
其中,节点3是第一个模式串的结尾字符(在原模式串中的位置是4,从1开始计数);第三个模式串的结尾字符(在原模式串中的位置是12);它的fail指向节点5(在原模式串中的位置是8)。
节点5是第二个模式串的结尾字符(在原模式串中的位置是8)。
在进行模式匹配的时候,在某个模式子串匹配成功之后,则根据其记录的位置信息,来判断起始点所在的位置,然后在这个位置上加1。最后就可以得到查询字符串在每个位置上的count值。
比如,当查询字符串是“ACGATCTCTCGATC”的时候,在匹配到第5个字符的时候(绿色,从0开始计数),自动机走到节点3,那么可以推出起点可能在查询字符串的第2个位置,将该位置的count值加1:
0 0 1 0 0 0 0 0 0 0 0 0 0 0
在匹配到第7个字符串的时候,自动机走到节点5,那么可以推出起点的位置不在查询字符串上,此时,不修改count值:
0 0 1 0 0 0 0 0 0 0 0 0 0 0
在匹配到第9个字符(蓝色)的时候,自动机走到节点5,那么起点可能在查询字符串第2个位置,将该位置的count值加1:
0 0 2 0 0 0 0 0 0 0 0 0 0 0
在匹配到第13个字符(黄色)的时候,自动机走到节点3,那么,可以推出起点可能在查询字符串的第2个、第6个、第10个位置,将这些位置上的count值加1:
0 0 3 0 0 0 1 0 0 0 1 0 0 0
最后,可以看到第3个位置的count值,和模式子串的数量相同,因此,得出通配符模式串匹配成功,在查询字符串上的起点是3。
# coding: utf8
import re
# 所有异常类的基类
class FilterSensitiveWordsException(BaseException):
pass
# AC自动机已经构建完毕时,添加敏感词或再次构建时,引发该异常
class ACAlreadyBuiltException(FilterSensitiveWordsException):
pass
# 添加的敏感词和过滤的字符串必须是unicode的,否则抛出该异常
class InvalidEncodingException(FilterSensitiveWordsException):
pass
# AC自动机尚未构建时,使用它过滤敏感词,引发该异常
class ACNotYetBuiltException(FilterSensitiveWordsException):
pass
# 模式串格式不正确时,抛出该异常
class InvalidPatternException(FilterSensitiveWordsException):
pass
# Trie树节点
class _Node(object):
def __init__(self):
self._subnodes = {}
self._is_end = False
self._fail = None
def set_default(self, character):
if character not in self._subnodes:
self._subnodes[character] = _Node()
return self._subnodes[character]
def get_subnode(self, character):
return self._subnodes.get(character, None)
def mark_as_end(self):
self._is_end = True
@property
def is_end(self):
return self._is_end
def iter_subnodes(self):
for character, subnode in self._subnodes.iteritems():
yield character, subnode
def set_fail(self, node):
self._fail = node
def get_fail(self):
return self._fail
# AC自动机实现
class FilterSensitiveWords(object):
def __init__(self):
self._is_built = False
self._root = _Node()
self._node_to_pattern = {}
def add_sensitive_word(self, sensitive_word, pattern, offsets, total_count):
"""向trie树增加敏感词"""
if self._is_built:
raise ACAlreadyBuiltException
if not isinstance(sensitive_word, unicode):
raise InvalidEncodingException
tmp = self._root
for character in sensitive_word:
tmp = tmp.set_default(character)
tmp.mark_as_end()
d = self._node_to_pattern.setdefault(tmp, {})
d[pattern] = {
"offsets": offsets,
"total_count": total_count}
def build(self):
"""生成fail指针"""
if self._is_built:
return
self._is_built = True
# 根节点的fail指针是null
self._root.set_fail(None)
queue = [self._root]
while queue:
node = queue.pop(0)
for character, subnode in node.iter_subnodes():
queue.append(subnode)
# 根节点的孩子节点的fail指针都指向根节点
if node is self._root:
subnode.set_fail(self._root)
continue
# f是node的fail指针指向的节点
f = node.get_fail()
while f is not None:
q = f.get_subnode(character)
if q is not None:
subnode.set_fail(q)
break
f = f.get_fail()
else:
# 指向根节点
subnode.set_fail(self._root)
def _get_output(self, p, ind, matching_patterns, string_length):
outputs = {}
while p is not None:
if not p.is_end:
p = p.get_fail()
continue
for pattern, info in self._node_to_pattern[p].iteritems():
if pattern not in matching_patterns:
matching_patterns[pattern] = [0] * string_length
# 将可能的起始位置都增加1
for offset in info["offsets"]:
for pos in range(offset[0], offset[1]+1):
start = ind - pos + 1
if start >= string_length or start < 0:
continue
matching_patterns[pattern][start] += 1
if matching_patterns[pattern][start] >= info["total_count"]:
outputs.setdefault(start, []).append([pattern, ind])
# 只返回不重叠的匹配
del matching_patterns[pattern]
break
p = p.get_fail()
return outputs
def _merge(self, d1, d2):
for k, v in d2.iteritems():
if k not in d1:
d1[k] = v
continue
d1[k].extend(d2[k])
def filter(self, string):
if not isinstance(string, unicode):
raise InvalidEncodingException
if not self._is_built:
raise ACNotYetBuiltException
matching_patterns = {}
string_length = len(string)
tmp = self._root
outputs = {}
for ind, character in enumerate(string):
while tmp is not None:
next = tmp.get_subnode(character)
if next is None:
tmp = tmp.get_fail()
continue
if next.is_end:
self._merge(outputs,
self._get_output(next, ind,
matching_patterns, string_length)
)
tmp = next
break
else:
tmp = self._root
return outputs
class Pattern(object):
_reg_exp = re.compile(r"(?P\s*\{\s*(?P\d+)\s*\}\s*|"
"\s*\{\s*(?P\d+)\s*,\s*(?P\d+)\s*\}\s*)", re.U)
def __init__(self, pattern):
self._pattern = pattern
self._tokens = self._parse_pattern(self.__class__._reg_exp, pattern)
self._result, self._count = self._get_word_position(self._tokens)
def _parse_pattern(self, reg_exp, pattern):
tokens = []
while pattern:
pattern = pattern.strip()
m = reg_exp.search(pattern)
if m is None:
break
first_part, pattern = pattern.split(m.group("splitter"), 1)
if m.group("first"):
first = int(m.group("first"))
repeat = (first, first)
else:
repeat = (int(m.group("second")), int(m.group("third")))
# 对repeat进行检查
if not (0 <= repeat[0] <= repeat[1]):
raise InvalidPatternException
first_part = first_part.strip()
if first_part:
tokens.extend([first_part, repeat])
else:
tokens.extend([repeat])
if pattern:
tokens.append(pattern)
return tokens
def _get_word_position(self, tokens):
index = 0
length = len(tokens)
result = {}
base = 0, 0
count = 0
while index < length:
element = tokens[index]
if isinstance(element, tuple):
if index == length - 1:
break
next_element = tokens[index + 1]
if isinstance(next_element, tuple):
raise InvalidPatternException
next_element_length = len(next_element)
base = base[0] + element[0] + next_element_length, \
base[1] + element[1] + next_element_length
result.setdefault(next_element, []).append(base)
count = count + 1
index = index + 2
continue
base = base[0] + len(element), base[1] + len(element)
result.setdefault(element, []).append(base)
count = count + 1
index = index + 1
return result, count
def iter_words(self):
for word, offsets in self._result.iteritems():
yield word, offsets
def get_pattern(self):
return self._pattern
def get_count(self):
return self._count
if __name__ == "__main__":
def myprint(r):
print u"\033[33m过滤结果:\033[0m"
for pos, patterns in r.iteritems():
print u" 位置:%s" % pos
print " " + "\n ".join(
[u"%s, %d"%tuple(pattern) for pattern in patterns]
)
ac = FilterSensitiveWords()
for pattern_string in [
u"日{0,3}本",
u"日{0,3}本{0,3}鬼{0,3}子",
u"大{0,3}傻{0,3}叉",
u"狗娘养的"]:
print u"\033[31m敏感词:%s\033[0m" % pattern_string
pattern = Pattern(pattern_string)
for word, offsets in pattern.iter_words():
ac.add_sensitive_word(word, pattern.get_pattern(),
offsets, pattern.get_count())
ac.build()
string = u"大家都知道:日(大)本(傻)鬼(叉)子都是狗娘养的"
string = u"日日本本鬼子"
print u"\033[32m过滤语句:%s\033[0m" % string
myprint(ac.filter(string))