目录
bitmap算法
位图是内存中连续的二进制位,每个位用于标识一个元素的状态(支持0、1两个状态)。bitmap通常用于对大量的整型数据进行去重和查询。
下面的例子中,将整数4、3、2、1依次插入到一个包含8个bit的bitmap中:
初始时,bitmap中所有位都为0(状态0用蓝色标识,表示元素不存在)

对于整数4,它的状态会被保存到索引为4的位置上,将此bit置为1(状态1用红色标识,表示元素存在)

对于整数3,它的状态会被保存到索引为3的位置上,将此bit置为1

对于整数2,它的状态会被保存到索引为2的位置上,将此bit置为1

对于整数1,它的状态会被保存到索引为1的位置上,将此bit置为1

接下来的例子是bitmap的一个使用场景:
开发一个用户画像系统,实现用户信息的标签化,并支持通过用户标签进行用户统计。该需求的实施过程可能类似下面的步骤:
1,建立用户名和ID的映射。比如,you -> 1、me -> 2、she -> 3
2,对于每一个标签,都使用一个独立的bitmap存储包含此标签的所有用户的ID。比如:
男:[1, 2]

女:[3]

程序员:[1, 2]
爱旅游:[1, 3]

3,进行统计。比如:
- 男性程序员:110 & 110 = 110,也就是ID为1和ID为2的用户是男性程序员
- 爱旅游的女性:1010 & 1000 = 1000,也就是ID为3的用户是爱旅游的女性
使用Python实现bitmap
bitmap通常基于数组来实现,数组中的每个元素被当成一个二进制数,所有的元素组成一个更大的二进制数。一个有符号整型占4个字节,也就是32位,其中最高位注释1是符号位(不可用),所以包含31个可用位。
创建一个包含N个bit的bitmap,需要N / 31 + 1个整数。对于整数num,它会被保存到第num / 31个整数的第num % 31个bit上。
下面附上代码:
xxxxxxxxxxclass Bitmap(object): def __init__(self, max): self._array = [0 for _ in range(max / 31 + 1)] def test(self, num): return self._array[num / 31] & (1 << (num % 31)) != 0 def set(self, num): element = self._array[num / 31] self._array[num / 31] = element | (1 << (num % 31)) def clear(self, num): element = self._array[num / 31] self._array[num / 31] = element & (~(1 <<(num % 31)))if __name__ == "__main__": from unittest import TestCase, main class BitmapTest(TestCase): def setUp(self): self._bitmap = Bitmap(63) def testTest(self): num = 63 self.assertFalse(self._bitmap.test(num)) self._bitmap.set(num) self.assertTrue(self._bitmap.test(num)) def testClear(self): num = 33 self._bitmap.set(num) self.assertTrue(self._bitmap.test(num)) self._bitmap.clear(num) self.assertFalse(self._bitmap.test(num)) main()bitmap排序
bitmap排序的基本思路是:
- 找出数组中的最大的元素,然后用它生成一个bitmap
- 将数组中的元素依次插入到bitmap中
- 遍历bitmap中的每个bit,如果该bit被设置过,输出该bit的位序(位序就是待排序数组中的元素)
下面附上代码:
xxxxxxxxxxdef bitmap_sort(array): if not array: return max = None min = None for element in array: if max == None or max < element: max = element if min == None or min > element: min = element bitmap = Bitmap(max) for element in array: bitmap.set(element) for ind in range(min, max+1): if bitmap.test(ind): print(ind)bloom filter
bloom filter利用位数组表示一个集合,并能判断一个元素是否属于这个集合。bloom filter的核心思想是:通过引入多个哈希函数的方式,减少冲突。如果通过这些哈希函数中的某一个得出元素不在集合中,那么该元素肯定不在集合中;如果通过所有的哈希函数都得出元素在集合中,那么该元素可能在集合中。bloom filter的特点是:它允许"误判",但不允许"漏判",因此它适合能容忍低错误率的场景,不适合"零误判"的场景。
bloom filter包含一个位数组和k个独立的哈希函数。
(1)位数组:
假设bloom filter使用一个m比特的数组保存信息。初始时,数组中的每一位都被置为0
(2)k个独立的哈希函数
bloom filter使用k个独立的哈希函数,它们分别将每个元素映射到{1…m}的范围中
当向bloom filter中增加任意元素x的时候,首先对x使用这k个哈希函数,得到k个哈希值,然后将位数组中对应的比特位都设置为1。比如:
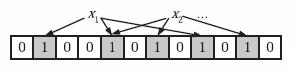
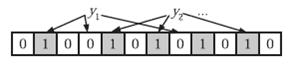
在判断任意元素y是否属于集合时,首先对y使用这k个哈希函数,得到k个哈希值,如果位数组中对应的比特位都为1,则认为y在集合中;否则,认为y不在集合中。比如:
参考文档
- https://www.cnblogs.com/wade-luffy/p/7718579.html
- https://blog.csdn.net/scdxmoe/article/details/49452607
- https://www.toutiao.com/i6682223935796281863/
- https://www.cnblogs.com/zhxshseu/p/5289871.html
注释
注释1
一个字节包含8个比特,这8个比特的编号分别是0、1、2、3、4、5、6、7。其中,bit7是最高位,bit0是最低位。与本博文的例子中展示的一样,在书写时,bit0在最右端,bit7在最左端