目录
前言
本文主要介绍 Ansible 中一些重要概念和特性。不能覆盖 Ansible 的全部特性以及细节。
预备知识
- ssh:http://timd.cn/ssh/
- yaml:http://timd.cn/yaml/
- jinja2: http://timd.cn/jinja2/
概述
Ansible 是一个 IT 自动化工具。可以用于:
配置管理
应用程序部署
执行 ad-hoc 任务
- 所谓的 ad-hoc 就是“临时命令”,注重于解决一些简单的或临时遇到的任务
多节点编排。比如零停机滚动升级等
Ansible 具有如下特点:
Ansible 的开发语言是 Python
Ansible 系统由控制主机和被管理主机组成
no agents/no server:控制主机默认通过 ssh 连接被管理主机,因此 Ansible 架构无服务端,去中心化。只需要简单的复制操作,就可以完成控制主机的迁移。同时,被管理主机上无需安装 agent
基于模块工作,可以使用任何语言开发模块
基于推送的方式:由调用者控制变更在被管理主机上的发生时间
许多自带模块提供幂等判断机制,这意味着多次执行相同的任务是安全的
- 比如通过 cron 模块添加定时任务时,如果任务已经存在,那么不会重复添加
playbook 使用 yaml 编写
Ansible 架构
Ansible 的整体架构如下图所示:
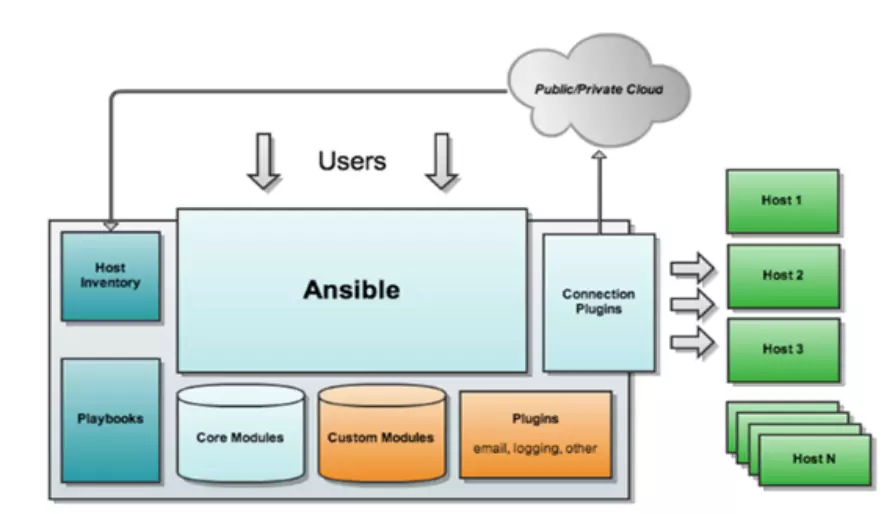
- Host Inventory:由 Ansible 管理的主机的清单。其中包含主机名、主机变量、主机分组、组变量
- Connection Plugins:Ansible 使用连接插件连接到被管理主机。默认使用 ssh
- Plugins:插件用来扩展 Ansible 的核心功能。Ansible 通过调用插件,完成特定的功能。比如调用 Inventory 插件,获取主机清单
- Core Modules:在 Ansible 中执行任务本质上就是调用模块
- Custom Modules:用户添加的扩展模块
- Playbook:用来编排高级的、复杂的任务
Ansible 执行任务的流程,大致如下:

额外说明
1,Ansible 有两种任务执行模式:
- ad-hoc 模式:用于执行简单的、临时的任务
- playbook 模式:用于编排高级的、复杂的任务
2,尽量使用 Ansible 自带的模块,而不是 shell 脚本,因为 Ansible 的很多模块提供幂等判断机制
3,模块和插件的区别:
- 模块会被上传到被控制主机上,在被控制主机上执行
- 插件在控制主机上,被 Ansible 调度执行
快速入门教程
1,安装 Ansible:
xxxxxxxxxxsudo pip install ansible2,Ansible 按照如下的优先级顺序地查找配置文件:
- ANSIBLE_CONFIG 环境变量
- ~/.ansible.cfg
- /etc/ansible/ansible.cfg
3,Ansible 配置文件:
(下面仅列出少数参数)
x
[defaults]# 指定 Inventory 文件的位置,默认值是 /etc/ansible/hostsinventory = /etc/ansible/hosts
# forks 是非常重要的、优化时需要重点关注的参数。# + Ansible 会创建 forks 个子进程,并发地管理多台被控主机。# + 默认值是 5,随着被管理主机的增多,需要适当调大forks = 5
# Ansible 在通过 ssh 连接被控主机时,是否检查其公钥host_key_checking = False
# ssh 连接的超时时间,单位是秒timeout = 60
# 指定存储 Ansible 日志的文件(默认不记录日志)log_path = /var/log/ansible.log
[ssh_connection]# 设置 Ansible 通过 ssh 连接被控主机时,使用的参数ssh_args = -o ControlMaster=auto -o ControlPersist=60s4,Inventory 文件:
既可以使用静态 Inventory 文件,也可以使用动态 Inventory。使用动态 Inventory 的好处是:可以根据其它系统(比如 CMDB、LDAP 等)动态地生成主机清单,避免产生需要在多个地方维护服务器列表的情况。
动态 Inventory 是一个可执行程序,Ansible 会创建一个子进程执行该程序,然后从该子进程的标准输出获取主机清单。因此,可以用任何语言编写动态 Inventory 程序,只要该程序满足 Ansible 的规范即可。(更多关于如何编写动态 Inventory 的细节,请移步参考文档)
可以在 Inventory 中对主机进行分组。Ansible 可以同时操作属于同一个组的多台主机。在定义主机时,可以为主机指定主机变量。也可以为组指定组变量(相当于同时为组内的所有主机指定变量)。这些变量可以被插件(比如连接插件)、模块等使用。
下面是一个非常简单的 Inventory 示例:
[mongodb]mongodb-101 ansible_ssh_host=192.168.10.101mongodb-102 ansible_ssh_host=192.168.10.102
[mongodb:vars]ansible_ssh_private_key_file=/etc/ansible/id_rsa5,执行 ad-hoc 任务:
使用 ansible 命令,执行 ad-hoc 任务。其使用方法是:
ansible <host-pattern> [-f forks] [-m module_name] [-a args]其中:
- <host-pattern>:用于对主机和分组进行过滤
- -f:用于指定启动多少个子进程
- -m:用于指定模块名
- -a:用于指定传递给模块的参数
比如使用 yum 模块,在所有主机上安装最新版本的 httpd-tools:
ansible all -m yum -a "name=httpd-tools state=latest" -bansible内建数百个模块。可以使用ansible-doc -l 列出所有模块。还可以使用 ansible-doc -s <module_name> 查看模块的用法。
playbook
playbook 是由一个或多个 play 组成的列表。play 的目标是:将一组主机映射到若干个预先好定义的角色上(角色中包含要调用的任务、要使用的变量等)。playbook 通过编排 play,完成复杂的功能。
play 由以下部分组成:
Target Section:
- hosts:用于指定在哪些主机上运行 play
- remote_user:用于指定在远程主机上,以哪个用户的身份执行任务
- ...
Variable Section:定义运行 play 时,使用的变量
Task Section:定义要在远程主机上运行的任务列表
name:任务的名字。用来描述任务是做什么的
'module: options':调用的 module 和传递给 module 的参数
notify:用于指定通知哪些 handler
- 需要注意的是:默认情况下,仅在任务执行成功,并且远程主机发生变动的情况下,才会执行 notify
...
Handler Section:定义在远程主机发生变动时,运行的操作
- handler 本质上也是 task
- 对于 handler 而言,即使它被 notify 多次,也只会在 play 中的所有 task 都执行完之后,执行一次
- Ansible 按照 handler 被声明的顺序执行它们
接下来看一个示例 playbook:
xxxxxxxxxx---hostswebservers remote_userroot
tasksnameensure apache is at the latest version yum namehttpd statelatestnamewrite the apache config file template src/srv/httpd.j2 dest/etc/httpd.conf
hostsdatabases remote_userroot
tasksnameensure postgresql is at the latest version yum namepostgresql statelatestnameensure that postgresql is started service namepostgresql statestarted
...facts
可以通过 setup 模块,采集远程主机的基础信息(比如硬件、操作系统等信息),这些信息会被保存到 ansible_facts 变量中。
使用 playbook 时,默认开启 facts 采集。但由于该操作比较耗时,所以在不需要主机基础信息的情况下,应该考虑关闭采集。Ansible 也支持对采集结果进行缓存。
比如可以通过以下命令采集远程主机的所有 IPV4 地址:
ansible all -m setup -a 'filter=ansible_all_ipv4_addresses'role
角色是一种自动地加载特定的 vars_file、tasks 和 handlers 的方式,它基于特定的文件结构。通过使用角色对内容进行分组,可以方便地进行复用。
下面对角色目录结构进行说明:
xxxxxxxxxxrole_name/(以角色名命名的目录)tasks/:如果存在 main.yml,那么其中列出的 tasks 将被添加到 play 中所有 import_tasks 任务可以引用该目录中的文件,不必指明文件的路径handlers/:如果存在 main.yml,那么其中列出的 handlers 将被添加到 play 中vars/:如果存在 main.yml,那么其中列出的 variables 将被添加到 play 中defaults/:如果存在 main.yml,那么其中列出的 variables 将被添加到 play 中meta/:如果存在 main.yml,那么其中列出的 “角色依赖” 将被添加到 roles 列表中templates/:角色中的所有 templates 任务可以引用该目录中的文件,不必指明路径files/:角色中的所有 copy 和 script 任务可以引用该目录中的文件,不必指明路径
需要说明的是:tasks、handlers、vars 等子目录都不是必须的。
在下面的例子中,定义了一个名称为 example 的角色:
xxxxxxxxxx# roles/example/tasks/main.ymlnameadded in 2.4, previously you used 'include' import_tasksredhat.yml whenansible_facts'os_family'|lower == 'redhat'import_tasksdebian.yml whenansible_facts'os_family'|lower == 'debian'
# roles/example/tasks/redhat.ymlyum name"httpd" statepresent
# roles/example/tasks/debian.ymlapt name"apache2" statepresent在这个例子中,角色会根据远程主机的操作系统类型,导入相关的任务。(import_tasks 用于导入任务列表)
Ansible 配置文件中的 roles_path 参数是冒号分隔的路径列表,Ansible 会去这些路径下寻找角色。比如:
xxxxxxxxxx[defaults]roles_path = /etc/ansible/roles可以通过 play 的roles选项使用角色:
xxxxxxxxxx---hostswebservers rolescommonwebservers条件选择
可以通过 when 语句实现:在某些条件满足的情况下,才执行任务或使用角色。在 when 语句中,可以使用 jinja2 表达式。比如:
x
tasksname"shutdown Debian flavored systems" command/sbin/shutdown -t now whenansible_os_family == "Debian"在这个例子中,仅当远程主机的操作系统类型是 Debian 时,才执行关机命令。
如欲了解更多关于条件选择的细节,可以查看官方文档。
循环
可以通过循环实现:使用不同参数,多次执行同一个任务。比如向远程主机批量添加用户:
x
---
hostsall gather_factsno becomeyes become_userroot tasksnameadd users username=item state=present looptestuser1testuser2
...如欲了解更多关于循环的细节,可以查看官方文档。
关于大规模集群的一些思考
当集群规模变大时,主控机的压力会随之增大。因此需要寻找一些方式,降低主控机的压力,从而避免出现性能瓶颈。下面是博主整理的一些方案:
按业务线对服务器进行分组,将大集群拆分成若干个规模较小的集群
分批次执行任务。这样做有两点好处:
- 如果正在执行的操作有误,可以减小故障影响
- 单次操作的服务器规模将变小
下发文件时,走专门的下载通道,降低主控机压力
对主控机做备份。因为主控机具有较高权限,重新授权代价较大
异步地执行任务。后文介绍
使用 ansible-pull。后文介绍
异步地执行任务
Ansible 支持异步地执行任务,即:在将任务下发之后,不再保持连接,而是每隔一段时间轮询一次执行结果,直到任务完成。
想要让任务异步地执行,需要在 task 中,加入两个参数:async 和 poll。
其中:
- async 用于指定任务执行时间的上限。如果任务的执行时间超过该上限,则认为任务执行失败。如果未设置该参数,那么将同步地执行任务
- poll 用于指定轮询的时间间隔。0 表示不关心任务的执行结果
比如:
x
---
hostsall gather_factsno tasksnamesleep for a while command/bin/sleep 10s async20 poll2
...如果想要更方便地查看轮询结果,可以使用 async_status 模块,比如:
x
---
hostsall gather_factsno tasksnamesleeper command/bin/sleep 30s async40 poll0 registerjob_sleeper
namechecker async_statusjid=job_sleeper.ansible_job_id retries30 registerjob_checker untiljob_checker.finished
...在这个例子中:
第一个任务是异步任务,其执行结果将被注册到 job_sleeper 变量中。
第二个任务使用 async_status 模块轮询第一个任务的执行结果,并返回轮询结果,最多轮询30次。
ansible-pull
Ansible 默认使用推模式,而 ansible-pull 使用拉模式。
其原理是:去指定的仓库上拉取 playbook,然后在本机执行。比如:
x
ansible-pull -o -C master -U https://github.com/tim-chow/ansible-pull-test.git -d /home/vagrant/ansible-pull-test -i ansible/hosts main.yml其中:
- -U:playbook 源的 URL
- -C:要检出的分支/tag/提交
- -i:指定 inventory 路径或逗号分隔的主机列表
- -d:仓库检出目录的绝对路径(不支持相对路径)
- main.yml:要执行的 playbook,可以是任意名字
- -o:仅当仓库被更新时,才执行 playbook
Inventory 中需要增加主机记录:
xxxxxxxxxxlocalhost# 或主机 hostname# 或 127.0.0.1# 具体原因请参考:https://stackoverflow.com/questions/55820887/how-to-resolve-warning-could-not-match-supplied-host-pattern-ignoring-machin/58032754因为 VCS 可以水平扩展,所以 ansible-pull 也可以做到水平扩展。
ansible-pull 通常与crontab 一起使用,这样可以做到:定期地在本地执行 playbook。
参考文档
TODO
自定义插件和模块
- 扩展 Ansible 的功能。比如可以通过定义新回调机制,在 playbook 执行成功时,给各部门发送邮件,组织新一轮测试工作,以免去人工干预;在 playbook 执行失败时,发送短信给开发人员,以尽快人工干预,排查错误等
为 Ansible 开发更友好的 Web 客户端