视觉及浏览器 Agent
赋予 Agent 视觉能力对于解决文本处理之外的任务至关重要。许多现实世界的挑战,比如网页浏览或文档理解,都需要分析丰富的视觉内容。幸运的是,smolagents 提供对视觉语言模型(VLM)的内置支持,使得 Agent 能够高效地处理和解释图像。
在下面的示例中,假设韦恩庄园的管家 Alfred 负责验证参加派对的客人的身份。Alfred 可能不认识到场的每一位客人。为帮助他,可以使用 Agent,该 Agent 通过 VLM 搜索关于客人外貌的视觉信息,验证他们的身份。这将帮助 Alfred 做出明智的决定,确定谁可以进入。
1. 在 Agent 执行开始时提供图像
在这种方式中,在开始时就将图像传递给 Agent,将其作为 task_images 与任务提示词一起存储。Agent 在执行过程中将持续处理这些图像。
假设 Alfred 需要验证参加派对的超级英雄们的身份。他已经拥有包含往期派对宾客照片及其姓名的数据集。当看到新访客的照片时,Agent 可以将其与现有数据集进行比对,从而决定是否允许他们入场。
在这种情况下,有位客人试图进入,而 Alfred 怀疑这位访客可能是小丑假扮的神奇女侠。Alfred 需要验证他们的身份,防止任何不速之客闯入。
下面构建该示例。首先,需要加载图像。为保持简单,该示例使用维基百科的图片。
from PIL import Image
import requests
from io import BytesIO
image_urls = [
"https://upload.wikimedia.org/wikipedia/commons/e/e8/The_Joker_at_Wax_Museum_Plus.jpg", # Joker image
"https://upload.wikimedia.org/wikipedia/en/9/98/Joker_%28DC_Comics_character%29.jpg" # Joker image
]
images = []
for url in image_urls:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
response = requests.get(url,headers=headers)
image = Image.open(BytesIO(response.content)).convert("RGB")
images.append(image)拥有这些图像后,Agent 将告诉我们这位客人到底是超级英雄(神奇女侠)还是反派(小丑)。
from smolagents import CodeAgent, OpenAIServerModel
model = OpenAIServerModel(model_id="gpt-4o")
# Instantiate the agent
agent = CodeAgent(
tools=[],
model=model,
max_steps=20,
verbosity_level=2
)
response = agent.run(
"""
Describe the costume and makeup that the comic character in these photos is wearing and return the description.
Tell me if the guest is The Joker or Wonder Woman.
""",
images=images
)在我的运行情况下,输出结果如下所示,不过正如之前所讨论,你运行时的结果可能有所不同:
{
'Costume and Makeup - First Image': (
'Purple coat and a purple silk-like cravat or tie over a mustard-yellow shirt.',
'White face paint with exaggerated features, dark eyebrows, blue eye makeup, red lips forming a wide smile.'
),
'Costume and Makeup - Second Image': (
'Dark suit with a flower on the lapel, holding a playing card.',
'Pale skin, green hair, very red lips with an exaggerated grin.'
),
'Character Identity': 'This character resembles known depictions of The Joker from comic book media.'
}在这种情况下,输出结果揭示这个人在冒充他人,所以可以阻止小丑混入派对!
2. 通过动态检索提供图像
之前的方式很有价值,并且有许多潜在的应用场景。然而,当访客不在数据库中时,则需要寻找其它身份识别方式。一个可能的解决方案是从外部来源动态获取图像和信息,比如通过浏览网络获取详细信息。
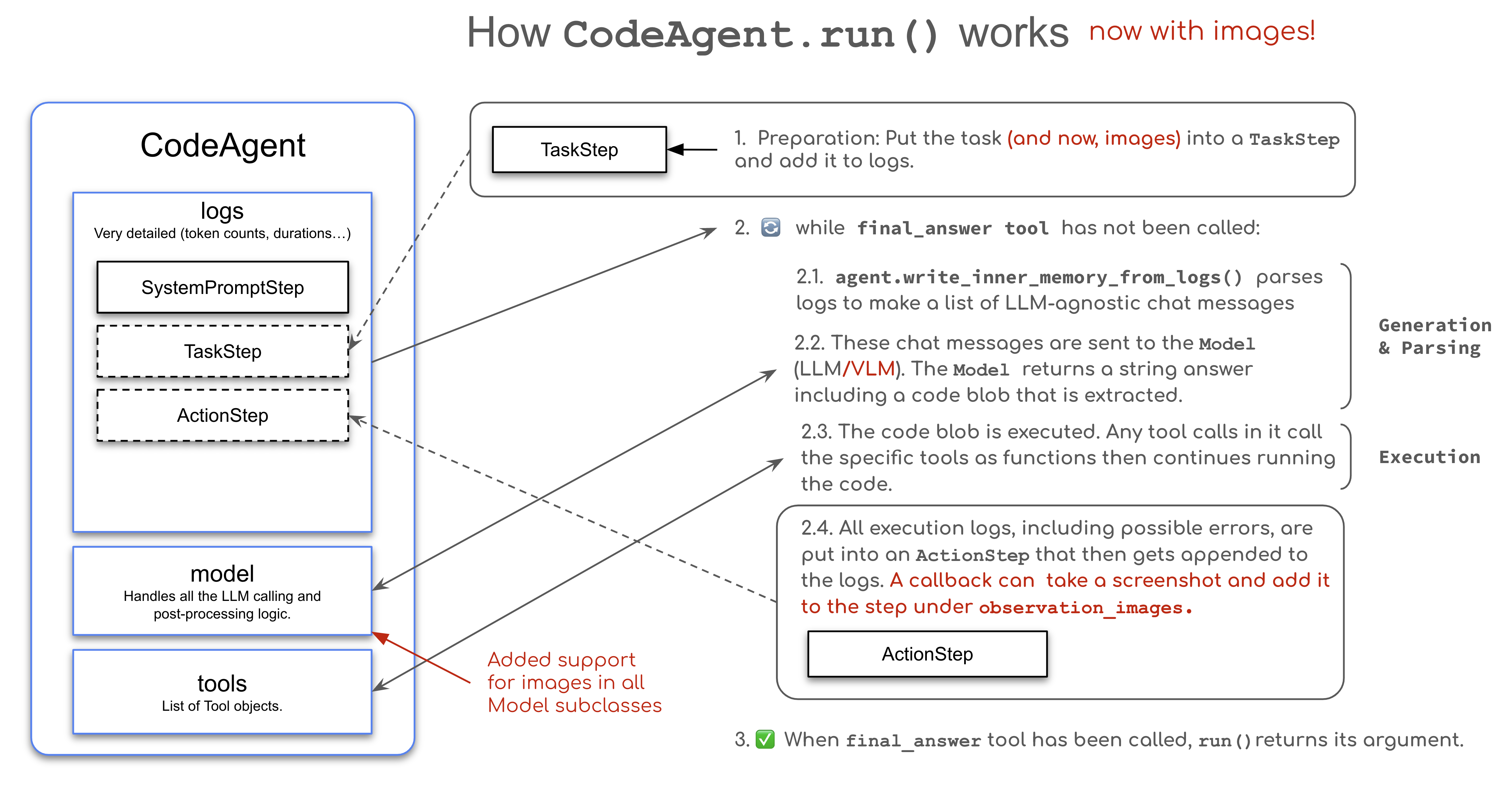
在这种方式中,图像在执行过程中被动态地添加到 Agent 的记忆系统中。如我们所知,smolagents 中的 Agent 基于 MultiStepAgent 类,它是 ReAct 框架的抽象。这个类运行在结构化的循环中,在不同阶段将记录各种变量和知识:
- SystemPromptStep: 存储系统提示词
- TaskStep:记录用户查询和所有提供的输入
- ActionStep:从 Agent 的行动和结果捕获日志
该结构化方式使 Agent 能够动态地整合视觉信息,并且能够适应性地响应不断演化的任务。下图展示动态工作流处理以及不同步骤如何在 Agent 生命周期中集成。在浏览过程中,Agent 可以截取屏幕截图,并且将其作为观测图像(observation_images)保存到 ActionStep 中。
下面构建完整的示例。在该示例中,Alfred 希望完全控制访客验证流程,因此一个可行方案是浏览详细信息。为完成该示例,需要为 Agent 配备新工具。此外,本示例将使用 Selenium 和 Helium 这两个浏览器自动化工具。这将使我们能够构建可以浏览网络的 Agent,用于搜索潜在访客的详细信息,并且获取验证信息。下面安装所需的工具:
pip install "smolagents[all]" helium selenium python-dotenv我们需要一套专门为浏览设计的 Agent 工具,比如 search_item_ctrl_f(页面搜索)、go_back(返回)和 close_popups(关闭弹窗)。这些工具使 Agent 能像人一样浏览网页。
@tool
def search_item_ctrl_f(text: str, nth_result: int = 1) -> str:
"""
Searches for text on the current page via Ctrl + F and jumps to the nth occurrence.
Args:
text: The text to search for
nth_result: Which occurrence to jump to (default: 1)
"""
elements = driver.find_elements(By.XPATH, f"//*[contains(text(), '{text}')]")
if nth_result > len(elements):
raise Exception(f"Match n°{nth_result} not found (only {len(elements)} matches found)")
result = f"Found {len(elements)} matches for '{text}'."
elem = elements[nth_result - 1]
driver.execute_script("arguments[0].scrollIntoView(true);", elem)
result += f"Focused on element {nth_result} of {len(elements)}"
return result
@tool
def go_back() -> None:
"""Goes back to previous page."""
driver.back()
@tool
def close_popups() -> str:
"""
Closes any visible modal or pop-up on the page. Use this to dismiss pop-up windows! This does not work on cookie consent banners.
"""
webdriver.ActionChains(driver).send_keys(Keys.ESCAPE).perform()我们还需要保存截图的功能,因为这是 VLM Agent 的重要组成部分。该功能捕获截图,将其保存在 step_log.observations_images = [image.copy()] 中,使 Agent 能够在运行过程中动态地存储和处理图像。
def save_screenshot(step_log: ActionStep, agent: CodeAgent) -> None:
sleep(1.0) # Let JavaScript animations happen before taking the screenshot
driver = helium.get_driver()
current_step = step_log.step_number
if driver is not None:
for step_logs in agent.logs: # Remove previous screenshots from logs for lean processing
if isinstance(step_log, ActionStep) and step_log.step_number <= current_step - 2:
step_logs.observations_images = None
png_bytes = driver.get_screenshot_as_png()
image = Image.open(BytesIO(png_bytes))
print(f"Captured a browser screenshot: {image.size} pixels")
step_log.observations_images = [image.copy()] # Create a copy to ensure it persists, important!
# Update observations with current URL
url_info = f"Current url: {driver.current_url}"
step_log.observations = url_info if step_logs.observations is None else step_log.observations + "\n" + url_info
return将该函数作为 step_callback 传递给 Agent,在 Agent 执行过程中,每个步骤结束时都将触发该函数。这使得 Agent 能够在整个处理过程中动态地捕获和存储截图。
现在生成视觉 Agent 浏览网站,同时为其提供刚才创建的工具,以及用于网络搜索的DuckDuckGoSearchTool。该工具将帮助 Agent 基于视觉线索获取验证访客身份所需的信息。
from smolagents import CodeAgent, OpenAIServerModel, DuckDuckGoSearchTool
model = OpenAIServerModel(model_id="gpt-4o")
agent = CodeAgent(
tools=[DuckDuckGoSearchTool(), go_back, close_popups, search_item_ctrl_f],
model=model,
additional_authorized_imports=["helium"],
step_callbacks=[save_screenshot],
max_steps=20,
verbosity_level=2,
)Alfred 已经准备好检查访客的身份,并且就是否允许他们参加派对做出决定:
agent.run("""
I am Alfred, the butler of Wayne Manor, responsible for verifying the identity of guests at party. A superhero has arrived at the entrance claiming to be Wonder Woman, but I need to confirm if she is who she says she is.
Please search for images of Wonder Woman and generate a detailed visual description based on those images. Additionally, navigate to Wikipedia to gather key details about her appearance. With this information, I can determine whether to grant her access to the event.
""" + helium_instructions)任务中包含 helium_instructions。这个特殊的提示词旨在控制 Agent 的导航行为,确保它在浏览网页时遵循正确的步骤。
最终输出如下:
Final answer: Wonder Woman is typically depicted wearing a red and gold bustier, blue shorts or skirt with white stars, a golden tiara, silver bracelets, and a golden Lasso of Truth. She is Princess Diana of Themyscira, known as Diana Prince in the world of men.