构建web应用的时候,往往需要在“真正的web服务”的基础上,增加一些通用功能,比如记录日志、授权管理、请求速率限制等。对于HTTP请求来说,API Gateway扮演着网关的角色,也可以说是进入系统的唯一节点,API Gateway能够集中地控制和管理通用的功能。
下面是一个来自Mashape Kong的对比:
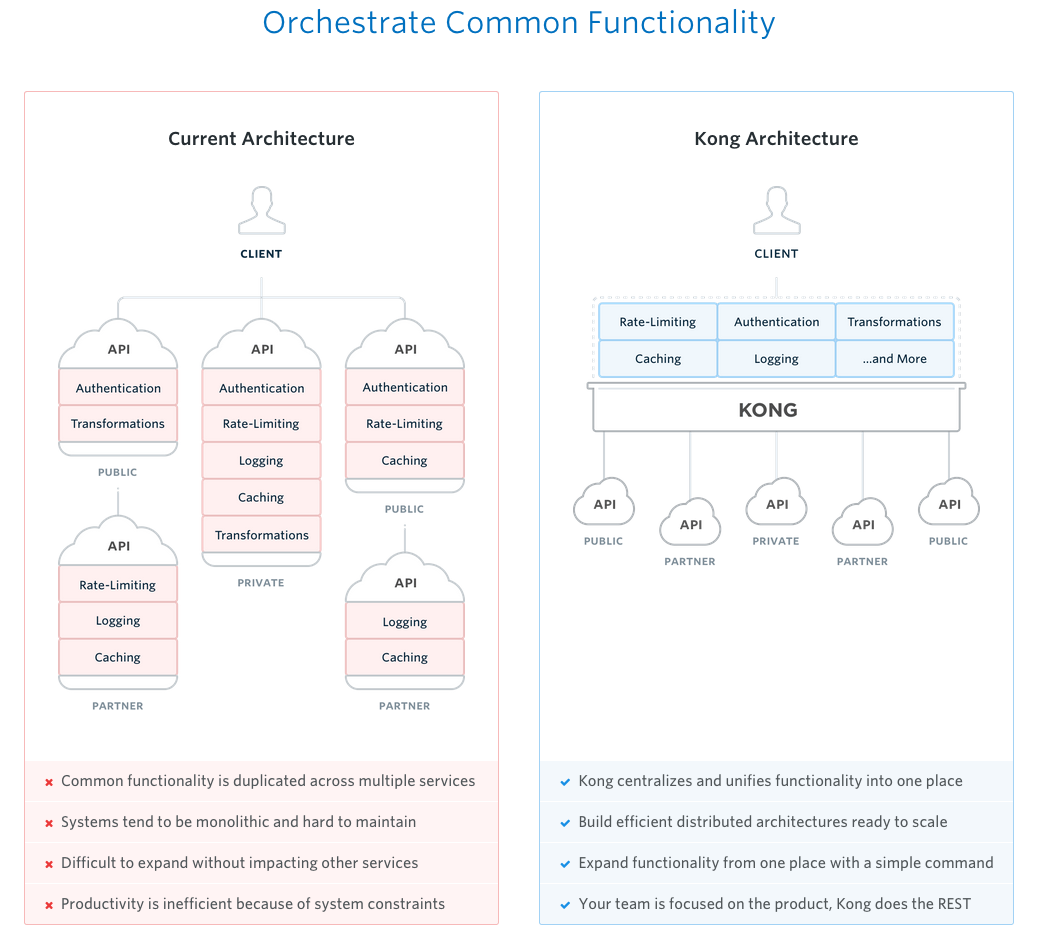
在当前的架构中:
在API Gateway架构中:
目前,API Gateway已经成了AWS的一项重要业务,下面两张图分别展示了亚马逊API Gateway调用流程,以及亚马逊API Gateway请求处理流程:
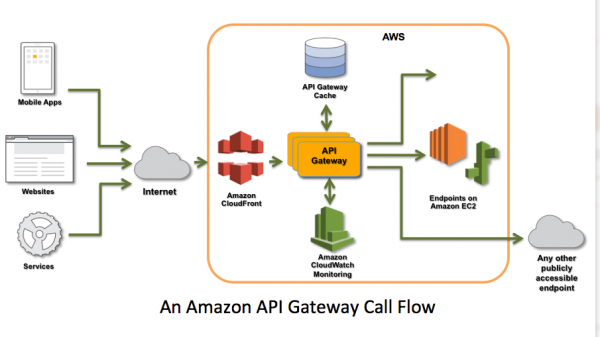
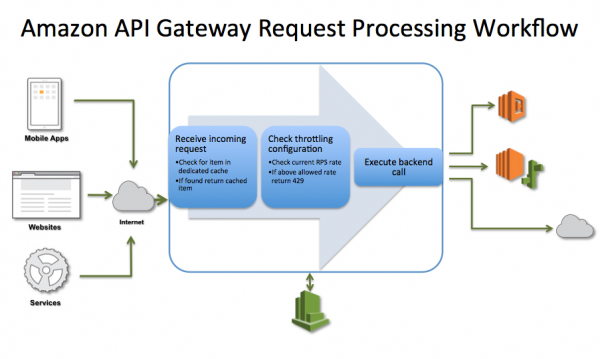
在这里要特别强调的是,上文中提及的Mashape Kong。Kong是一个基于ngx_lua实现的API Gateway,github上的地址是:https://github.com/Mashape/kong。
VIPServer是阿里中间件团队开发的一个中间层负载均衡(mid-tier load balancing)产品,VIPServer基于P2P模式,是一个七层负载均衡产品。VIPServer提供动态域名解析和负载均衡服务,支持很多诸如多业务单元同单元优先、同机房优先、同区域优先等一系列流量智能调度和容灾策略,支持多种健康监测协议,支持精细的权重控制,提供多级容灾体系、具有对称调用、健康阈值保护等保护功能的解决方案。(上面的介绍摘自http://www.woaiit.com/news/2016052713841.html)
下面开始介绍VIPServer的原理:
假设有一个内部服务A和一个内部服务B,在服务A中需要调用服务B,那么通常情况下时序图可能如下所示:
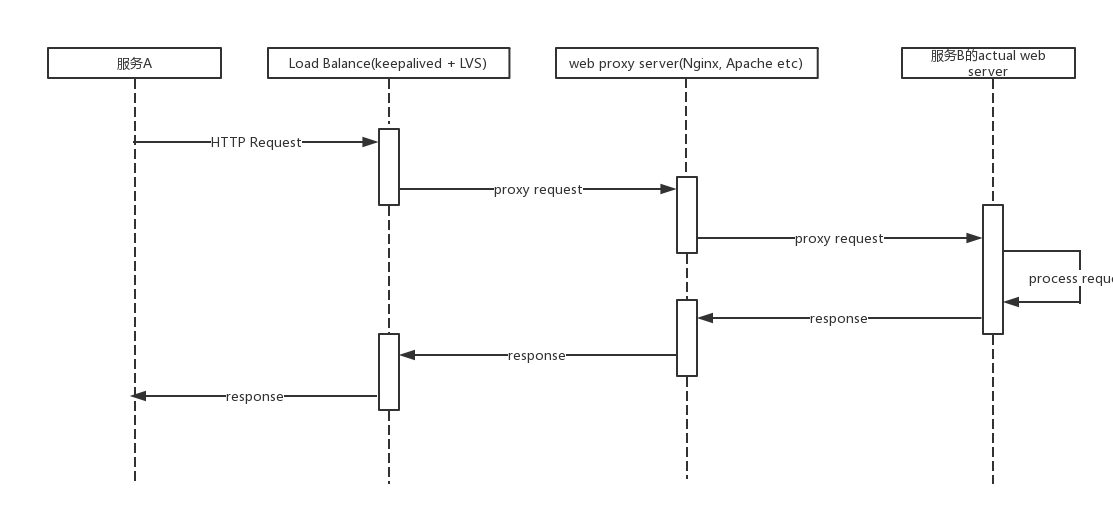
其中:Load Balance层可能是公用的,而每一个服务都有自己的web proxy server和actual web server。
在当前的架构中,有一个缺点:服务间的请求需要经过多层转发,才能到达真正处理请求的后端服务器。当内部服务的数量增大时,服务之间的请求数量也会变得极为可观,如果为了保证高可用,每个服务都使用了公共的内网LVS的话,那么LVS本身的带宽都会成为瓶颈。阿里开发VIPServer的原因之一就是:内网LVS的带宽被跑满。
下面是博主整理的VIPServer工作原理简图:
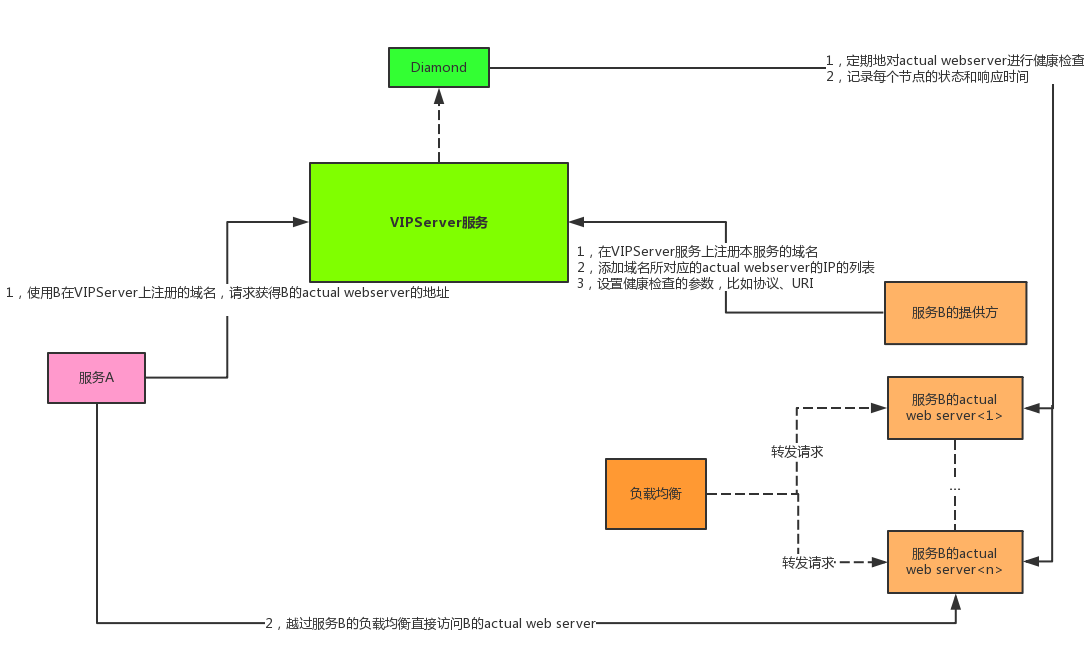
VIPServer服务的大体功能包括:
上图中没有体现出,但是需要特别说明的包括:
和VIPServer类似的产品是httpdns。
ngx-service-discovery是基于Openresty(ngx_lua)和Redis实现的一个Nginx自动发现后端upstream,以及对后端upstream进行健康检查的服务框架。里面有一些API Gateway和VIPServer的影子。
下面是该框架中的一些概念:
每个数据中心都有一个ID(数据中心ID的名字以DATA_CENTER-开头,比如DATA_CENTER-dc1)。数据中心也可以是虚拟的,比如可以创建一个ID为DATA_CENTER-dc1-and-dc2的数据中心,用来表示数据中心dc1加上数据中心dc2。这样做的主要目的是便于扩展
每个Nginx实例,都有一个节点类型(节点类型以NODE_TYPE-开头,同一个数据中心的不同Nginx实例的节点类型可以相同)。同时,Nginx也需要配置自己所在的数据中心。在ngx-service-discovery中,把NODE_TYPE-xxx@DATA_CENTER-yyy做为Nginx实例的ID
每个Nginx(用ID来区分,ID相同的Nginx共享相同的配置)都有一个存储在Redis中的配置,该配置用来说明Nginx将接收到的请求代理到哪个数据中心;备用的数据中心是什么;当满足AB Test条件时,将请求代理到哪个数据中心。数据中心可以是虚拟的,比如,建立虚拟数据中心DATA_CENTER-dc1-ABTest专门用来处理AB Test请求。我们将该配置称为Nginx ID配置。
Redis中的数据结构类似:
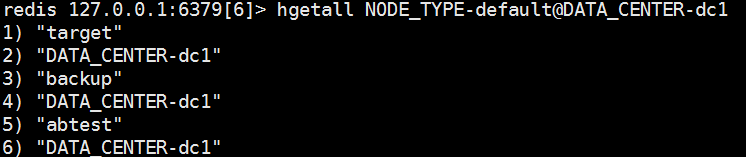
其中:hash表名表示Nginx ID,target表示要代理到的数据中心ID,backup表示备用的数据中心ID,abtest表示用来处理AB Test请求的数据中心ID

其中:hash表名表示数据中心ID;key代表后端节点的地址;value是json格式的,hostname表示该后端节点对应的域名,uripattern表示该后端节点能处理哪些uri,它是一个正则表达式,^/表示所有uri,checkpath是用于健康检查的地址,还可通过checktimeout设置健康检查时的超时时间,weight用于balance算法,表示权重。
当后端服务启动的时候,可以自己向Redis注册,一个后端服务可以注册到多个数据中心或虚拟数据中心上,比如服务127.0.0.1:80可以同时注册到DATA_CENTER-dc1和DATA_CENTER-dc1-ABTest,注册其实就是在一个或多个表示数据中心的hash表中增加一个key/value对,其中,key是服务的地址,value是相关的配置信息。也可以象VIPServer一样,由服务提供方通过web UI去注册
有了上面的概念之后,就可以很好的理解下面要阐述的服务是如何发现的了:
Nginx的worker进程在启动时候,会创建一个“后台任务”,该任务会周期性地轮询Redis,以获取关于Nginx ID和相关数据中心的配置,然后写入到worker内部的cache中。当Nginx向后端代理请求的时候,会从cache中获取后端节点,然后按照加权轮询算法,从其中选择一个后端节点。因此,后端服务只要把自己注册到Redis,就会被Nginx的后台任务轮询到,然后写进cache,进而在balance时被选择到
Nginx的worker进程在启动的时候,还会创建一个用于对后端节点进行周期性地健康检查的“后台任务”。假如,有100个后端节点1、...、100,该后台任务会创建一个大小可配置的“线程池”(在异步编程中,称为“协程池”更合适),假设“线程池”的大小是10,那么会先并发地检查后端节点1-10,等他们都检查完毕之后,再检查11-20,等等。对于某一个后端节点而言,如果健康检查失败了,则在cache中对该节点的计数增加1;如果健康检查成功了,则将cache中关于该节点的计数删除。Nginx在向后端代理请求的时候,首先会选择出目标后端节点的列表,然后使用健康检查cache中的计数信息(计数的数量代表连续失败次数)对目标后端节点列表进行过滤,比如后端节点的连续失败次数超过3次(可以配置)就认为是不健康的。在健康检查时,超时时间很重要,如果超时时间过长,那么会影响对其他节点的健康检查的时效性,同时“线程池”的大小也很重要
Nginx选择后端节点的粗略流程是:
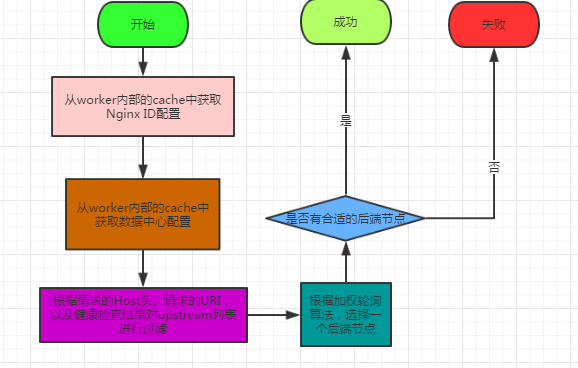
接下来用文字描述进行补充:
在Nginx ID配置中,保存的是Nginx需要将请求代理到哪个数据中心,包括target数据中心、backup数据中心、abtest数据中心;在数据中心配置中,保存的是某个数据中心上注册了哪些后端节点。
Balancer先去Nginx ID配置中获取到target数据中心和backup数据中心,再根据数据中心配置生成target后端节点列表和backup后端节点列表,接着用请求的host、uri以及健康检查的计数过滤这两个列表,最后根据负载均衡策略先从target后端节点列表中选择节点,然后将请求代理到该节点,如果没找到合适的,那么再去backup后端节点列表中选择,如何仍然没有合适的后端节点,那么服务返回500 INTERNAL ERROR。
因为数据中心信息、节点信息、节点健康信息都在cache中,如果通过一个接口将他们暴漏出来,那么这个接口就是一个弱化版的VIPServer。

注意:Nginx实例的节点类型是通过plugins/MyConfig.lua的NODE_TYPE配置项来配置的;Nginx实例所在的数据中心是通过plugins/MyConfig.lua的DATA_CENTER配置项来配置的。
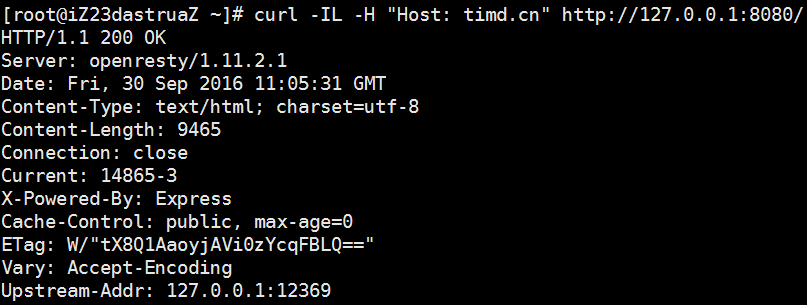
需要特别注意的是:在数据中心配置信息中,每个节点都有一个hostname和一个uripattern。Balancer在过滤后端节点列表的时候,会要求请求的host和节点的hostname相同,并且请求的uri与节点的uripattern(一个正则表达式)相匹配。测试时,要注意请求头中的Host头域和配置中节点的hostname。在生产中,将域名指向Nginx所在的服务器即可。
